GPU和深度学习——学习笔记
Last updated on:3 years ago
本着初学deep learning时要理解基本原理的原则,Dave把GPU和深度学习的关系理了一理。
GPU
图形处理器(Graphics processing unit, GPU)是一个特殊的电路回路,它被用来快速处理和转化内存,从而加速框架缓存器中图像的生成,并且输出给显示设备。在单片机、移动电话、PC、游戏主控等均有应用。现代的GPUs(加s表示复数)能够非常有效地进行计算机图形学处理和图像处理。GPUs有高度并行结构,从而使它们比传统的中央处理器(CPUs)更加容易并行处理大型数据。
具体来说,某个GPU在向桌面输送数据时,有包括超过100个处理内核工作,并且峰值内存带宽也比GPUs的大几倍。硬件可以同时与上千个线程一起工作。更主要的区别是,传统CPU是通过内核隐藏和控制流来工作的,而GPUs利用更多的晶体管作为逻辑运算单元然后更少地使用隐藏和流控制。这使得训练和内存获取的类型改变了,因此需要重新设计学习算法来满足这些限制。
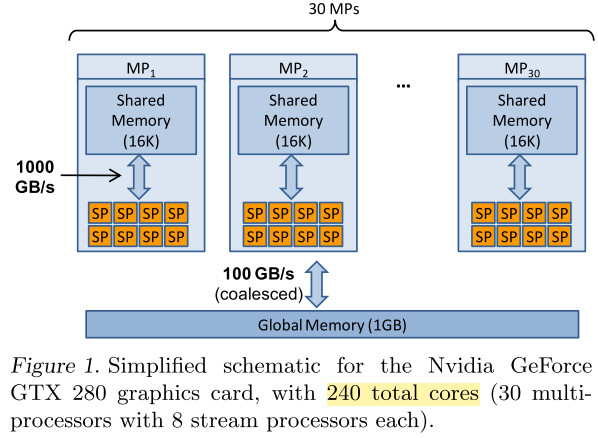
总结一下GPUs的特点:
- 内核量巨大,并行计算更方便
- 内存带宽大
- 可处理数量集更大
- 优化问题较CPU难

云GPUs和CPUs均可租赁。
CPU Memory Occupation
Dataloader 讀取數據效率太慢,考慮更高效的dataloader。
Python lists store only references to the objects, the objects are kept separately in memory. Every object has a refcount, therefore every item in the list has a refcount.
replace your lists / dicts in Dataloader getitem with numpy arrays.
If your Dataloaders iterate across a list of filenames, the references to that list add up over time, occupying memory.
Strictly speaking this is not a memory leak, but a copy-on-access problem of forked python processes due to changing refcounts. It isn’t a Pytorch issue either, but simply is due to how Python is structured.
Deep Learning Conception
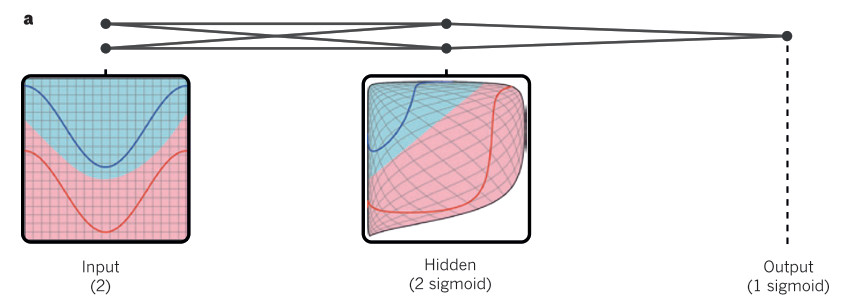

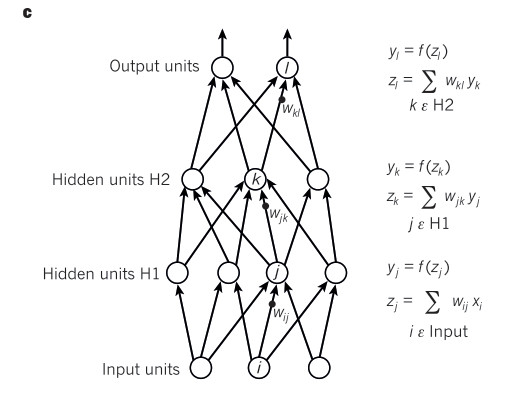
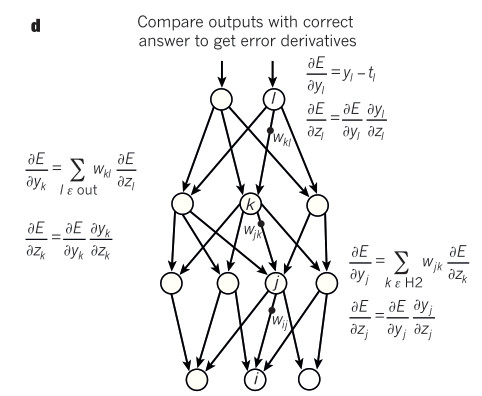
参考资料
[2] What is a GPU and do you need one in Deep Learning?
[3] LeCun, Y., Bengio, Y. and Hinton, G., 2015. Deep learning. nature, 521(7553), pp.436-444.
[4] Raina, R., Madhavan, A. and Ng, A.Y., 2009, June. Large-scale deep unsupervised learning using graphics processors. In Proceedings of the 26th annual international conference on machine learning (pp. 873-880).
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!