What is a foundation model?
Last updated on:4 months ago
A foundation model is a type of artificial intelligence (AI) model trained on vast and diverse datasets to perform a wide range of general tasks. These models act as a foundation for building more specialised applications and are often used in generative AI, where they can generate text, images, videos, and other forms of data.
![]()
Foundamental concepts of foundation models
Background
Foundation model (FM) is an AI model with broad capabilities, meaning it can process diverse data modalities and conduct heterogeneous tasks. FM can adapt to build specialised and advanced models or tools. The earlier form of foundation models is large language models (LLMs), which are usually used as a chatbot aligning with generating human-like text. In other words, LLMs are a subset of foundation models.
A new successful paradigm for building AI systems. Train one model on a massive amount of data and adapt it to many applications. Such a model is called a foundation model.
A foundation model is a robust, general-purpose AI developed through self-supervised pre-training on unlabelled data and equipped with billions of parameters. These models exhibit independent reasoning and execute complex tasks across a broad skillset. With multimodal and multidomain capabilities, they form the cornerstone for generative AI applications. Key attributes include:
- Expressivity: Capturing and representing diverse information flexibly.
- Scalability: Processing extensive data efficiently.
- Multimodality: Integrating different formats and domains.
- Memory Capacity: Storing substantial knowledge.
- Knowledge Organization: Distilling and organizing knowledge from various sources into scalable representations, enabling generalization to new contexts.
Foundation models a large-scale and pretrained deep-learning models adapted to a wide range of downstream tasks. Trained on large-scale datasets to bridge the gap between different modalities. Foundation models facilitate contextual reasoning, generalisation, and prompt capabilities.
Segment Anything Model (SAM) is a promotable model developed for broad image segmentation. It has been adapted to various downstream tasks, including medical image analysis, painting, style transfer, and image captioning.
Stanford Institute for Human-Centred AI: A foundation model is any model that is trained on broad data (generally using self-supervision at scale) that can be adapted (e.g., fine-tuned) to a wide range of downstream tasks.
Large language models
With the rise of LLMs, generative AI tools have become more common since an “AI boom” in the 2020s. This boom was made possible by improvements in transformer-based deep neural networks and large language models.
LLMs are trained on large datasets, learn patterns and structures from datasets, and generate coherent and contextually relevant text or responses/conversations.
All LLMs are foundation models, but not all foundation models are LLMs. Foundation generative AI models are distinct from other generative AI models because they exhibit broad capabilities that can be adapted to a range of different and specific tasks.
Foundation model vs. specialised model
Foundation model (FM) focuses on general and diverse tasks (e.g., text generation, translation, image generation) and requires significant computational cost.
Specialised model focuses on specific task (e.g., medical image classification), requiring less computational power.
Although some previous research of specialised models also related to multimodal learning, text generation, etc, they also concentrate on single or two tasks, lacking generalisability compared to the foundation model.
Foundation specifies these models’ role: a foundation model is itself incomplete but serves as the everyday basis from which many task-specific models are built via adaptation. Foundation connotes the significance of architecture stability, safety, and security: poorly constructed foundations are a recipe for disaster, and well-executed foundations are a reliable bedrock for future applications.
Major tools and applications
Chatbots/Text-to-text models
ChatGPT (Open AI), Copilot (GitHub), Gemini/Bard (Google), Grok (xAI), Llama (Meta), DeepSeek (DeepSeek), and AlphaCode.
ChatGPT is effective in generating dynamic responses and conversational flow. Gemini/Bard is optimal for researching current news or information.
Applications
Text completion, summarisation, question answering, translation, code generation, image and text pairing, conversational interactions.
Code and program functions.
Usage example
- Write a xxx about xxx
- Convert this xxx into a short story
- Create a summary of this story
An example:
“Summarise the article on ‘IBM Watson Assistant transforms content into conversational answers with generative AI’ based on the IBM blog post (https://www.ibm.com/blog/ibm-watsonx-assistant-transforms-content-into-conversational-answers-with-generative-ai/) into a small paragraph.”
Question 5
Harsh needs to monitor and detect anomalies in the company software to reduce downtime and prevent critical failures. Which tool can be used to do that?
-[x] NOLEJ (yes)
-[ ] Watson AIOps
-[ ] AIO Logic (wrong)
-[ ] DataRobot
Question 2
Which feature of large language models (LLMs) directly impacts their predictive accuracy?
-[ ] LLMs are pre-trained on unsupervised, unlabeled data (wrong)
LLMs are pretrained using convolutional networks
-[x] LLMs are pre-trained on billions of data parameters (yes)
The higher the number of bias and weight parameters, the stronger the computational power of the network, which leads to increased predictive accuracy.
LLMs are pre-trained using transformer-based models.
Question 2
Which code generation is based on the pre-trained language model OpenAI Codex tool and can help Elizabeth generate solution-based code?
-[ ] PolyCoder (Wrong)
-[ ] ChatGPT (Wrong)
-[x] GitHub Copilot (yes)
-[ ] Amazon CodeWhisperer
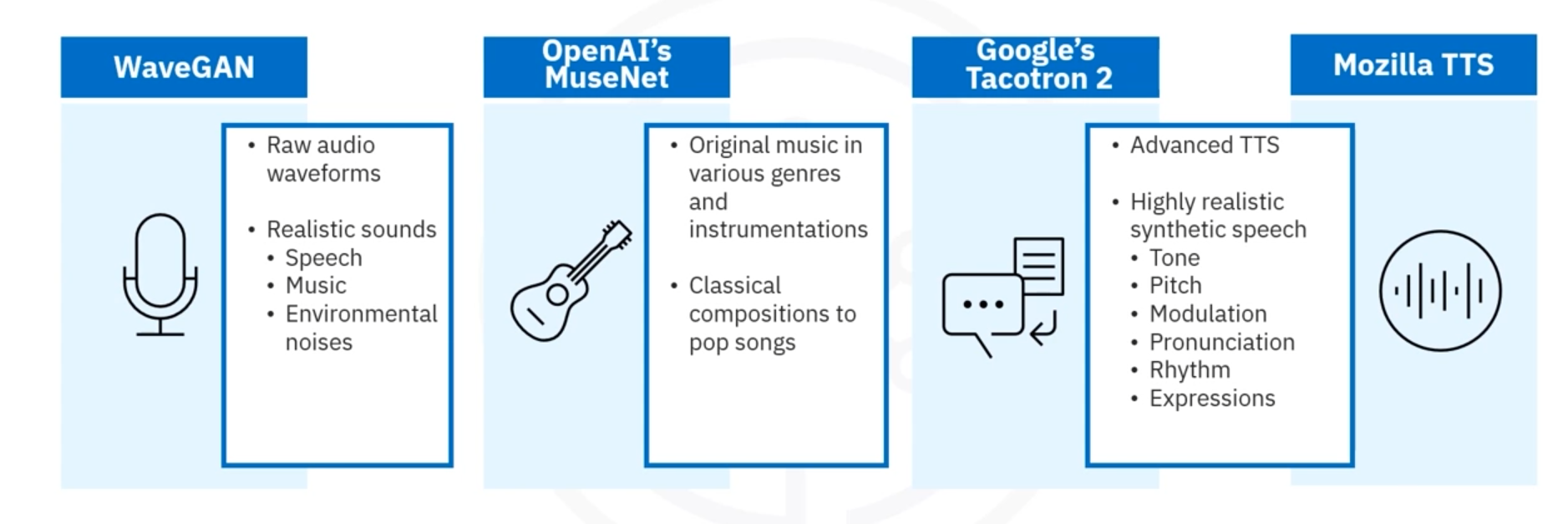
Text-to-audio models
WaveGAN, OpenAI’s MuseNet, Google’s Tacotron 2, and Mozilla TTS.
Applications
Synthetic voice and new audio.
Text-to-image models
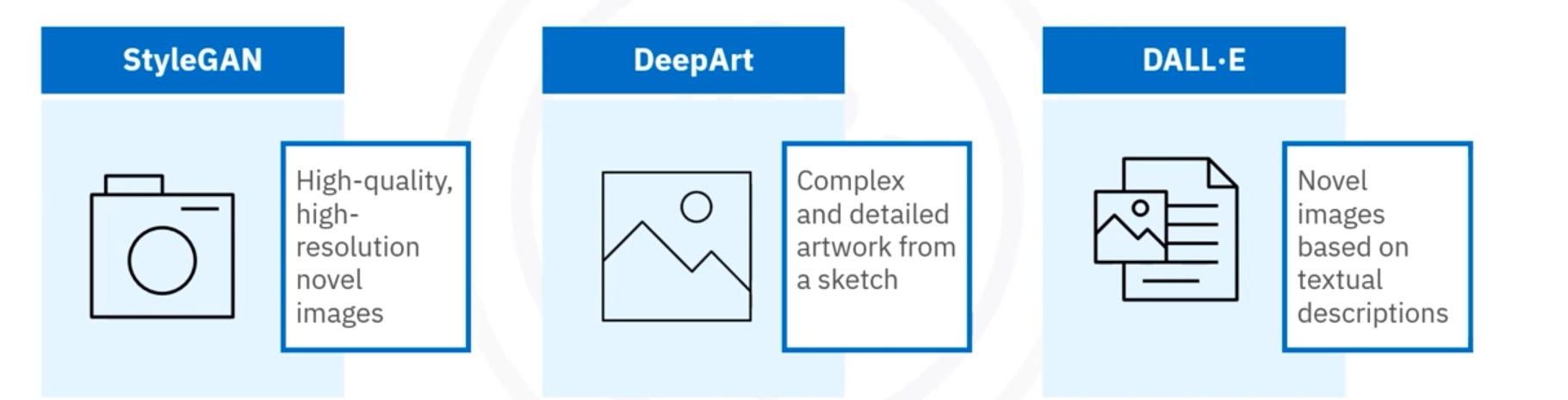
Stable diffusion, Midjourney, DALL-E, StyleGAN, DeepArt.
Generative AI models have advanced significantly in recent years, enabling the creation of new and realistic images using artificial intelligence techniques.
Applications
Create realistic textures, natural colours, fine-grained details, and high-quality images. Synthetic data to augment existing data sets.
- Text-to-image generation
- Image-to-image translation
- Style transfer and fusion
- Inpainting
- Outpainting
Virtual avatars and digital personalities.
A metaverse platform with generative AI capabilities will allow you to access virtual avatars, which is impossible with other generative AI tools.
![]()
DALL-E by OpenAI based on GPT can:
- Generate high-resolution images in multiple styles.
- New versions can generate multiple image variations.
- Uses in inpainting and outpainting.
Stable diffusion
- Open-source model.
- Creates high-resolution images.
- Generates images based on text prompts.
- Used for image-to-image translation, inpainting, and outpainting.
StyleGAN
- Enables precise control for manipulating specific features.
- Separates image content and image style.
- Evolved to generate higher-resolution images.
Usage example
A text prompt example:
“An illustration of a woman using an app in a smartphone to capture her skin images for self-examining melanoma at home, Trending on Artstation.”
Question 2
Tiana is designing a game and decides to create one avatar with specific personality traits. What type of generative AI capability is Tiana using?
-[ ] Ability to synthesise images (wrong)
-[ ] Ability to augment data
-[x] Ability to create virtual worlds (yes)
-[ ] Ability to generate dynamic films
Question 3
Which generative AI model is trained in a static environment and can rapidly reduce the dimensionality of your image, text, or audio?
-[x] Variational autoencoders (yes)
-[ ] Generative adversarial networks (wrong)
-[ ] Diffusion models
-[ ] Transformer-based models
Variational autoencoders can rapidly reduce the dimensionality of your image, text, or audio. Although trained in a static environment, they generate realistic and varied photos.
Text-to-video models
Synthesia, Sora.
Applications
Create dynamic and smooth videos.
Usage example
The prompt and output are different concepts. One is at the forefront of the model, and the other is at the end of the framework.
Question 4
What input data does VideoGPT best respond to?
-[ ] AI-generated code
-[ ] Image prompts
-[ ] Video prompts (wrong)
-[x] Text prompts (yes)
Applications
General language tasks
Generality and adaptability: a single foundation model can be adapted differently to achieve many linguistic tasks.
Tasks: classification, generation.
General vision tasks
Foundation models translate raw perceptual information from diverse sources and sensors into visual knowledge that may be adapted to many downstream settings. Example tasks: semantic understanding, geometric, and multimodal integration.
Challenges:
- Semantic systematicity and perceptual robustness.
- Computational efficiency and dynamics modelling.
- Training, environments, and evaluation.
Robotics
Challenges
- Data needs & challenges
- Safety & robustness
Healthcare and biomedicine
Both healthcare and biomedical research demand significant expenses, time, and comprehensive medical knowledge. The inefficiency and shortage in healthcare necessitate developing fast and accurate interfaces for healthcare providers and patients, such as automated aid systems for diagnosis/treatment, summarisation of patient records, and answering patient questions.
Applications:
- For healthcare providers: create summarises of patient visitation, retrieve relevant cases and literature, suggest lab tests, diagnosis, treatments and discharges, and help a surgical robot monitor and achieve accurate surgeries.
- For patients: provide relevant information about clinical appointments, answer patient questions related to preventive care, give relevant medical explanatory details, and help assistive-care robots for patients.
Opportunities:
- Drug discovery
- Personalised medicine
- Clinical trials
Challenges:
- Medical data are highly multimodal, with various data types (text, image, video, database, molecule), scale (molecule, gene, cell, tissue, patient, population), and styles (professional and lay language).
- Explainability: provides evidence and logical steps for decision-making, which is crucial in healthcare and biomedicine.
- Legal and ethical regulations: healthcare applications must observe legal and moral rules with guarantees, such as patient safety, privacy, and fairness.
- Extrapolation.
Law
Legal applications require that attorneys read and produce long, coherent narratives that incorporate shifting contexts and decipher ambiguous legal standards. Ample data exists in legal documents and their generative capabilities are well-suited to the many generative tasks required in law. Still, significant improvements are needed for foundation models to reason over various sources of information reliably.
Education
Open-ended generative (e.g., problem generation) and interactive (e.g., feedback to teachers) aspects.
Reasoning and search
The combinatorial search space renders traditional search-based methods intractable. Foundation models’ multi-purpose nature and their strong generative and multimodal capabilities offer new leverage for controlling the combinatorial explosion inherent to search.
Interaction
Foundation models lower the difficulty threshold for prototyping and building AI applications due to their sample efficiency in adaptation and raise the ceiling for novel user interaction due to multimodal and generative capabilities.
Economics, philosophy of understanding, and others …
Concept of prompt engineering
Introduction: what is a prompt?
A prompt is an input you provide/submit to a model (e.g., foundation model), guiding it to generate specific output or perform a discriminative task.
A proper prompt has context, adequate structure, and is comprehensible. It can be a series of instructions.
Key factors:
Instructions: give distinct guidelines regarding the task.
Context: provides a framework for generating relevant content
input data: any piece of the information supplied as part of prompt
output indicator: offers benchmarks for assessing attributes of the output
Prompt engineering means the process of designing practical, accurate, and contextually appropriate prompts. Importance of prompt engineering:
- Optimising model efficiency.
- Boosting performance for specific tasks.
- Understanding model constraints.
- Enhancing model security.
Vanilla input vs prompt
Compared to vanilla input, prompts are more related to an instruction or message to guide the model or user on what to input and how to interact.
Example:
Prompt: “Enter your name:”
Input: The user types their name (e.g., “John Doe”).
Device
To do prompt engineering, you need at least 8 RTX4090 for downstream task training. For pretraining, it would be > 32 A100. Therefore, it is not friendly for a small team to research that. Transfer learning can be applied to avoid hardware dependence.
Society
Inequity and fairness
It is essential for source tracing to understand ethical and legal responsibility. Various sources (e.g., training data, lack of diversity among foundation model developers, and the broader sociotechnical context) give rise to these biases and harms.Security and privacy
Foundation models are a high-leverage single point of failure. They may suffer from various security vulnerabilities (e.g., adversarial triggers to generate undesirable outputs) or privacy risks (e.g., memorisation of training data).Misuse
Foundation model misuses the use of foundation model as they are technically intended (e.g., to generate language or video), but to cause societal harm (e.g., to generate disinformation, to develop deepfakes for harassment).Environment
The energy required for this training coincides with the release of more carbon into the atmosphere and the degradation of the environment.Legality
Foundation models rest on weak legal footing at present. The pertinent liability issues for model predictions and protections from model behaviour are highlighted.Economics
Foundation models will likely have a substantial economic impact due to their novel capabilities and potential applications in various industries and occupations.
Prompt techniques
The process of using prompt
Here is the well-structured iterative process:
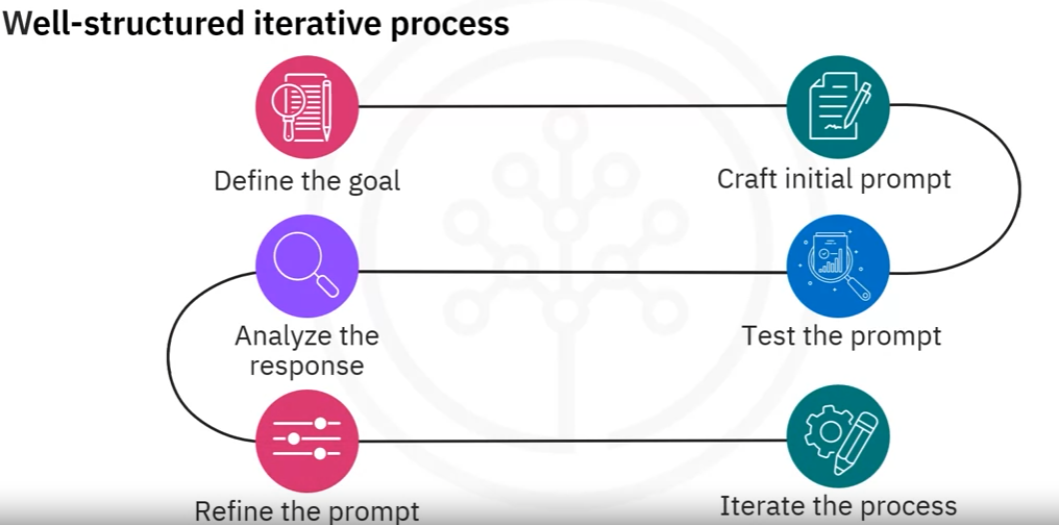
Defining the goal: e.g., give a brief overview of the benefits and risks of artificial intelligence in automobiles.
Craft initial prompt: e.g., write an article that presents a well-rounded analysis of the benefits and drawbacks associated with incorporating artificial intelligence in the automobile industry.
Test the prompt: e.g., write an article that presents a well-rounded analysis of the benefits and drawbacks associated with incorporating artificial intelligence in the automobile industry.
Analyse the response: e.g., fail to cover a comprehensive range of benefits and risks associated with artificial intelligence in the automobile industry.
Refine the prompt: e.g., write an informative article discussing the role of artificial intelligence in revolutionising the automobile industry.
And iterate the process: e.g., Write an article highlighting how artificial intelligence is reshaping the automobile industry, focusing on the positive advancements, particularly in autonomous driving and real-time traffic analysis, while thoroughly exploring concerns related to intricate technical aspects such as decision-making algorithms and potential cybersecurity breaches. Emphasise the implications these concerns may have on vehicle safety. Ensure the analysis is thorough, backed with examples, and encourages critical thinking.
Example
Best practices for writing effective prompts can be implemented across four dimensions: clarity, context, precision, and role-play.
- Clarity includes using concise and straightforward language
- Context provides background and required details
- Precision means being specific and providing examples
- Role-play enhances response by assuming a persona and offering relevant context
e.g.,
“You will act as a fitness expert current with the latest research data and provide detailed step-by-step instructions in reply to my queries.”
“Create a gym workout program to lose weight and build strength for an out-of-shape beginner.”
Prompt engineering tools: IBM prompt lab.

Question 1
How does the streamlined mode in PromptPerfect contribute to prompt optimisation?
-[ ] By selecting a relevant model for prompt optimisation
-[x] By refining prompts step-by-step until satisfied with the output (yes)
-[ ] By experimenting with the autocomplete feature
-[ ] By accessing prebuilt prompts as examples
Question 2
How does incorporating the persona pattern dimension enhance prompt effectiveness? Select the best option.
-[x] By introducing a sense of character-driven context and perspective
Question 3
What is the key benefit of incorporating examples within the prompt?
-[ ] It makes the prompt more concise.
-[x] It helps the model understand the desired purpose. (yes)
Text-to-text prompt techniques
Task specification, contextual guidance, domain expertise, bias mitigation, framing, zero-shot prompting, user feedback loop, explainability, and fostering user trust.
Question 4
Imagine you are a content developer working with LLMs and must ensure that the responses generated are indiscriminatory and neutral. Which techniques would you use with your text prompts to appropriately instruct the model?
-[x] Bias mitigation (yes)
-[ ] Few-shot prompting
-[ ] Contextual guidance
-[ ] Zero-shot prompting (wrong)
While ChatGPT, like any AI, may have inherent biases due to its training data, steps can be taken to mitigate them. Regular auditing, continuous learning from diverse datasets, and human oversight can help reduce the impact of these biases.
Zero-shot prompting means that the prompt used to interact with the model won’t contain examples or demonstrations. In natural language processing models, zero-shot prompting means providing a prompt not part of the training data to the model. Zero-shot prompting is a technique where an LLM is asked to perform a task without being given any specific examples or training data for that task. For instance, the LLM has been trained using dictionary data but is asked to produce news text.
Pattern approach
The user provides prompt instructions, the model asks necessary follow-up questions, the model draws information from the response, model processes the information to provide an optimised solution.
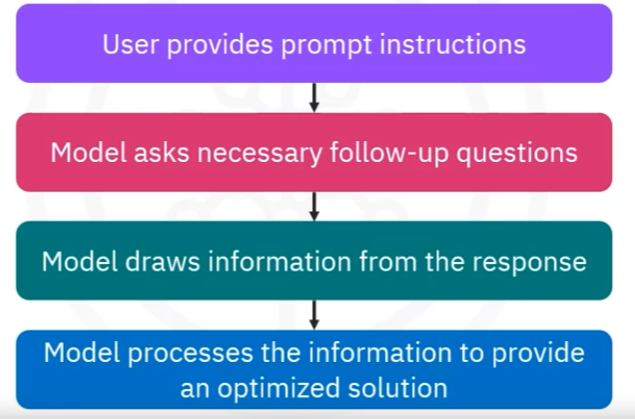
The model will ask for your preferences and adjust the itinerary accordingly.
Example 1:
e.g., “Ask me a series of questions, one by one, to gather all the information you need to respond properly.”
Example 2:
Naïve/standard prompt:
“Define a marketing plan for my online store, which sells shoes.”
Persona pattern:
“Acting as a marketing expert, define a marketing plan for my online store, which sells shoes.”
Question 3
How does the interview pattern approach enhance the interaction with generative AI models?
-[ ]By focusing on a conventional prompting approach
-[ ]By hierarchically structuring a prompt or query (wrong)
-[ ] By providing a single static prompt to the model.
-[x] By promoting a back-and-forth exchange of information with the model. (yes)
Chain-of-thought
Use a sequence of interconnected ideas or concepts that process logically, building upon each other to conclude.
Example:
e.g.,
“Bob is in the living room.”
“He walks to the kitchen, carrying a cup.”
“He puts a ball in the cup and carries the cup to the bedroom.”
“He turns the cup upside down, then walks to the garden.”
“He puts the cup down in the garden, then walks to the garage.”
“Where is the ball?”
Example 2:
Naïve/standard prompt:
“Define a marketing plan for my online store, which sells shoes.”
Tree-of-Thought Prompt Instructions:
“Imagine three different experts are answering this question.”
“All experts will write down 1 step of their thinking,
then share it with the group.”
“Then all experts will go on to the next step, etc.”
“If any expert realises they’re wrong at any point, they leave.”
Text-to-image prompt techniques
An image prompt is a text description of an image. Descriptors are used to influence the artistic style or visual attributes of images. Visual elements: colour, contrast, texture, shape, and size. A prompt can include information about:
- Miscellaneous art styles.
- Historical art periods.
- Photography techniques.
- Type of art materials used.
- Traits of well-known brands or artists.
Style modifiers

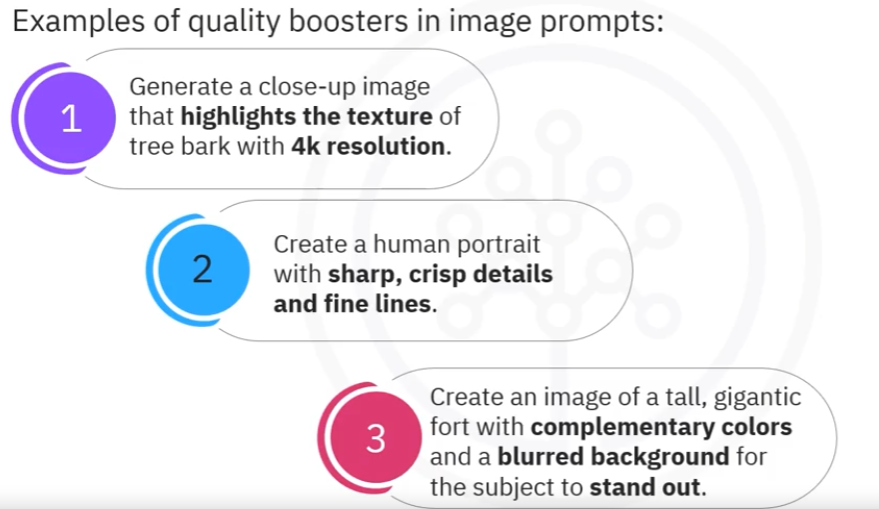
Quality boosters
e.g., use terms like high resolution, 2k, 4k, hyper-detailed, sharp focus, and complementary colours.
Repetition
Adjectives can be repeated many times to focus on a specific idea.

Weighted terms
Words or phrases that have a powerful emotional or psychological impact.

Fix deformed generation
The technique is used to modify deformities or anomalies that may impact the effectiveness of the image.

Reference
- Bommasani, R., Hudson, D.A., Adeli, E., Altman, R., Arora, S., von Arx, S., Bernstein, M.S., Bohg, J., Bosselut, A., Brunskill, E. and Brynjolfsson, E., 2021. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258.
- Moor, M., Banerjee, O., Abad, Z.S.H., Krumholz, H.M., Leskovec, J., Topol, E.J. and Rajpurkar, P., 2023. Foundation models for generalist medical artificial intelligence. Nature, 616(7956), pp.259-265.
- Zhang, S. and Metaxas, D., 2024. On the challenges and perspectives of foundation models for medical image analysis. Medical image analysis, 91, p.102996.
- Azad, B., Azad, R., Eskandari, S., Bozorgpour, A., Kazerouni, A., Rekik, I. and Merhof, D., 2023. Foundational models in medical imaging: A comprehensive survey and future vision. arXiv preprint arXiv:2310.18689.
- Bordes, F., Pang, R.Y., Ajay, A., Li, A.C., Bardes, A., Petryk, S., Mañas, O., Lin, Z., Mahmoud, A., Jayaraman, B. and Ibrahim, M., 2024. An introduction to vision-language modelling. arXiv preprint arXiv:2405.17247.
- Generative artificial intelligence
- Generative AI for Everyone
- Generative AI: Foundation Models and Platforms
- Building foundation model prompts
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!