MATLAB循环调用函数使用并行池指南(带非官方实际例子)
Last updated on:4 years ago
并行池这个东西,可以让MATLAB把你的CPU跑满,这也就意味着更快的运算速度,我结合我自己编的函数聊聊怎么用这个平行池。
当你需要不同参数循环调用同一个函数或者直接调用几个不同的函数,你可能会问,我的电脑配置还行,CPU和内存都还没跑满,那么我把这些都用上会不会运行快一点。这个时候平行池(Parallel Pool)就出现了,顾名思义,就是可以并行运行你的程序,比如利用两组参数同时调用同一个函数同时计算。
结果
下面是两组输入量的并行运行效果和直接循环运行效果,小虎的程序快了12秒。
Got result with index: 1.
Got result with index: 2.
Elapsed time is 131.705283 seconds.
Elapsed time is 143.168543 seconds.4组输入,也不知道为什么不并行慢了这么多:
Elapsed time is 519.250776 seconds.
Elapsed time is 1362.264277 seconds.并行池的配置

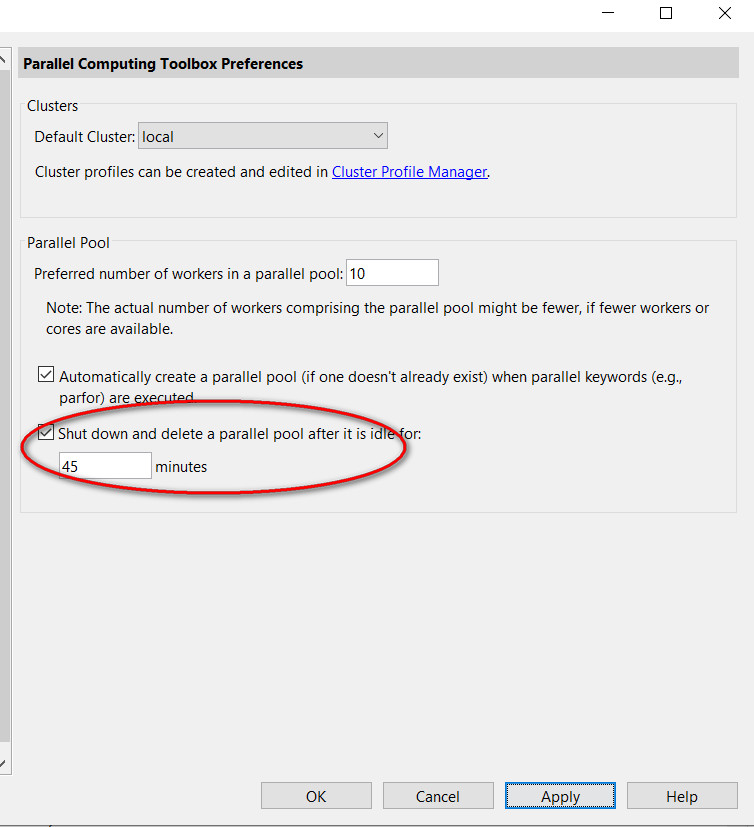
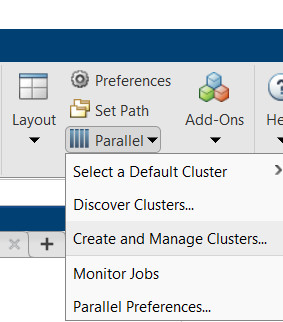
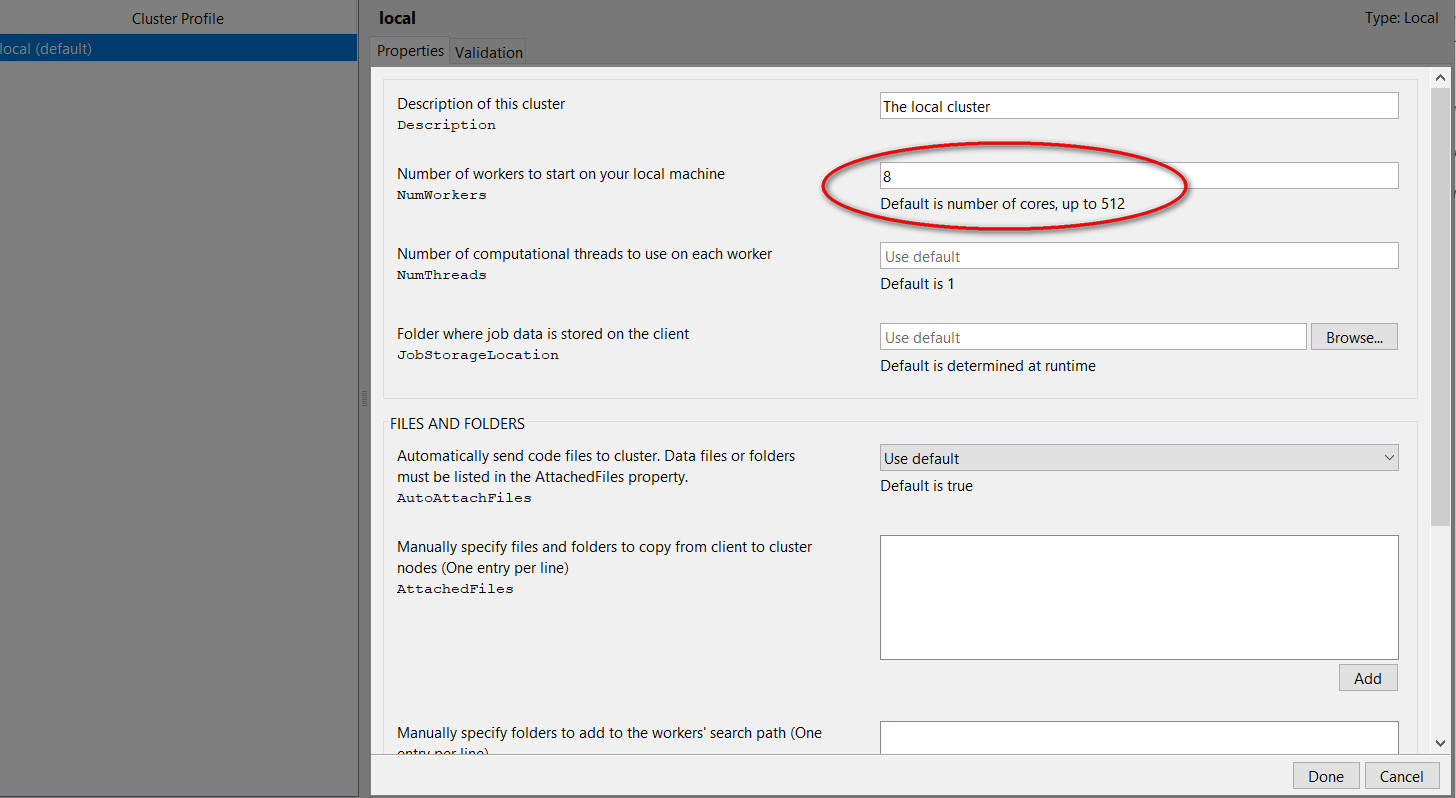
parfeval()函数
用途解释是Execute function asynchronously on parallel pool worker,就是说在不同时在平行池的worker中执行函数。但由于池比较宽,里面可以通的最大程序数比较多,我觉得这是在强调并行池也是有极限的。
语法
F = parfeval(p,fcn,numout,in1,in2,...)
F = parfeval(fcn,numout,in1,in2,...)p(pool)是并行池得一些其他配置,比如worker数量;fcn是输入的函数名;numout是函数输出参数的数量(可以是0);in1,in2,in3是输入的参数(有几个输入几个)。
并行池的使用
官方简单例程
我大概解读一下下面官方的代码。官方代码是打算并行运行10次magic(N)函数,idx是输入的参数N,也就是说有十组的输入数据,从1~10;这里用到了parfeval函数。第一个for循环时建立FevalFuture,将输入和函数名称绑定起来;结果将在第二个循环中的[completedIdx,value] = fetchNext(f)开始计算得出。
num = 10; % 自己取,测试一下
f(1:num) = parallel.FevalFuture;
for idx = 1:num
f(idx) = parfeval(@magic,1,idx);
end
magicResults = cell(1,num);
for idx = 1:num
[completedIdx,value] = fetchNext(f);
magicResults{completedIdx} = value;
fprintf('Got result with index: %d.\n', completedIdx);
end下面我给出它的等价程序。
%% unparallel
magicResults = cell(1,num);
%% parallel
for idx = 1:num
magicResults{idx} = magic(idx);
end加上计时试试。(第一行并行时间,第二行不并行时间)
num = 10;
Elapsed time is 0.264016 seconds.
Elapsed time is 0.000820 seconds.num = 1000;
Elapsed time is 11.995380 seconds.
Elapsed time is 3.562912 seconds.num = 1500;
Elapsed time is 28.925654 seconds.
Elapsed time is 12.127613 seconds.可以看到,时间的比越来越小了,不过,此程序非并行还是比较快。所以说,并行这东西要慎用。具体到哪个num并行比较快(甚至并行在这个程序就是比较慢?),我就不验证了,我的内存不够了。我的工程仿真项目中已经验证了,结果在文章前面。这个官方程序中,我加了workers的数量发现这个时间并没有太大变化,所以一般用4个就好。
工程项目仿真例程
循环调用的函数定义如下:
function kuangXiaoHu(FOI,sepparam,geoparam)我对程序进行了一些简化,只用了两组并行。
geoparam.shape = 2;
FOI = 'ellipsoid'; % field of interest
%% parallel
tic
idex = 0;
f1(1:2) = parallel.FevalFuture;
for theta = [30, 60]
SepParam.theta = theta;
idex = idex + 1;
f1(idex) = parfeval(@kuangXiaoHu,0,FOI,SepParam);
end
%%%%%% 求解
for idx = 1:num
completedIdx = fetchNext(f(idx));
magicResults{completedIdx} = value;
fprintf('Got result with index: %d.\n', completedIdx);
end
toc
%% unparallel
tic
for theta = [30 60]
sepparam.theta = theta;
kuangxiaohu(FOI,SepParam);
end
toc结果在开头看到了,快了10多秒(这还只是两组的,内存容许的情况下还可以多几组)。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!