Photo Optical Recognition/OCR - Class Review
Last updated on:4 years ago
Photo OCR is widely used in character classification. Meanwhile, ceiling analysis is also a practical method to help you know how to launch your effort.
Problem description and pipeline
Steps
- Text detection
- Character segmentation
- Character classification
Photo OCR pipeline
graph LR
A(Image) -->B(Text detection)
B --> C(Character segementation)
C --> D(Character recognition)Sliding windows

Getting lots of data and artificial data synthesis
The distortion introduced should be a representation of the type of noise/distortions in the test set
Usually does not help to add purely random/meaningless noise to your data
Discussion on getting more data
- Make sure you have a low bias classifier before expanding the effort
- How much work would it be to get 10x as much data as we currently have
Artificial data synthesis, collect/label it yourself, crowdsource.
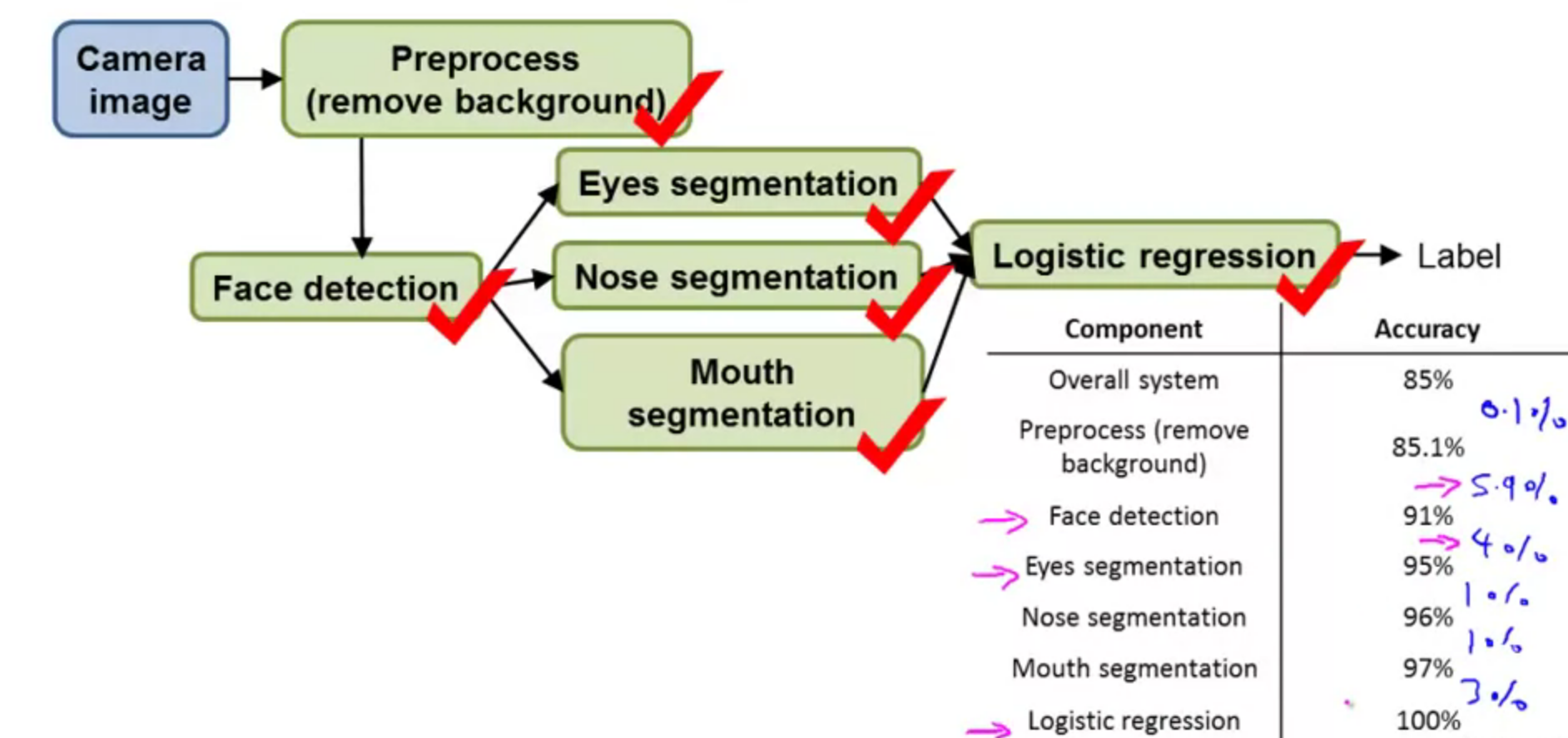
Ceiling analysis
What part of the pipeline to work on next?
Ceiling analysis is a method used to estimate which element of a pipeline machine learning system has a strong influence on the prediction. Likewise, it allows us to estimate which element has a weak influence, and therefore, to limit the effort to improve its performance as it yields no significant change in the final result.
| Component | Accuracy |
|---|---|
| Overall system | 72% |
| Text detection | 89% |
| Character segmentation | 90% |
| Character recognition | 100% |
Class exercises
Within classes
Q1: Suppose you are training a linear regression model with m examples by minimizing:
$$J( \theta) = \frac{1}{2m} \sum^m_{i=1} ((h_\theta (x^{i}) - y{(i)}) ^2)$$
Suppose you duplicate every example by making two identical copies of it. That is, where you previously had one example ($x^{(i)}$, $y^{(i)}$) you now have two copies of it, so you now have 2m examples. Is this likely to help?
- [x] No, and in fact, you will end up with the same parameters $\theta$ as before you duplicated the data.
Homework
Q1: Suppose you are running a sliding window detector to find text in images. Your input images are 1000x1000 pixels. You will run your sliding windows detector at two scales, l0x10 and 20x20 (i.e., you will run your classifier on lots of 10x10 patches to decide if they contain text or not; and also on lots of 20x20 patches), and you will “step” your detector by 2 pixels each time. About how many times will you end up
running your classifier on a single 1000x1000 test set image?
- [ ] l,000,000
- [ ] l00,000
- [x] 500,000
With a stride of 2, you will run your classifier approximately 500 times for each dimension. Since you run the classifier twice (at two scales), you will run it 2 * 500 * 500 = 500,000 times.
- [ ] 250,000
Q2: Suppose you perform ceiling analysis on a pipelined machine learning system, and when we plug in the ground-truth labels for one of the components, the performance of the overall system improves very little. This probably means: (check all that apply)
- [ ] We should dedicate significant effort to collecting more data for that component.
- [x] It is probably not worth dedicating engineering resources to improving that component of the system.
- [x] If that component is a classifier training using gradient descent, it is probably not worth running gradient descent for 10x as long to see if it converges to better classifier parameters
Reference
[1] Andrew NG, Machine learning
[2] Roncancio, H., Hernandes, A.C. and Becker, M., 2013, January. Ceiling analysis of pedestrian recognition pipeline for an autonomous car application. In 2013 IEEE Workshop on Robot Vision (WORV) (pp. 215-220). IEEE.
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!