Carrying out error analysis - Class review
Last updated on:3 years ago
With practical strategies to carry out error analysis, your can efficiently iterate your models.
Why human-level performance
Comparing to human-level performance, humans are quite good at a lot of tasks, so long as ML is worse than humans, you can:
- Get labelled data from humans.
- Gain insight from manual error analysis: why did a person get this right?
- Better analysis of bias/variance.
Avoidable bias
Human-level error as a proxy for Bayes error
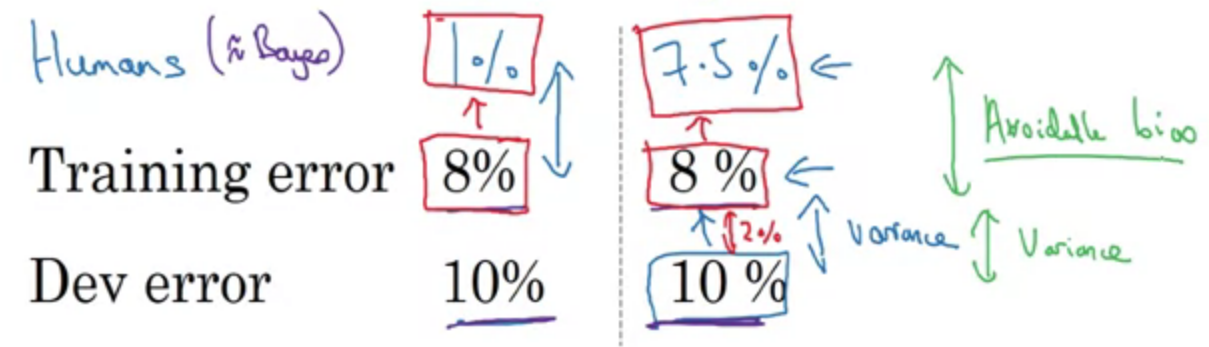
Surpassing human-level performance
Problems where ML significantly surpasses the human-level performance
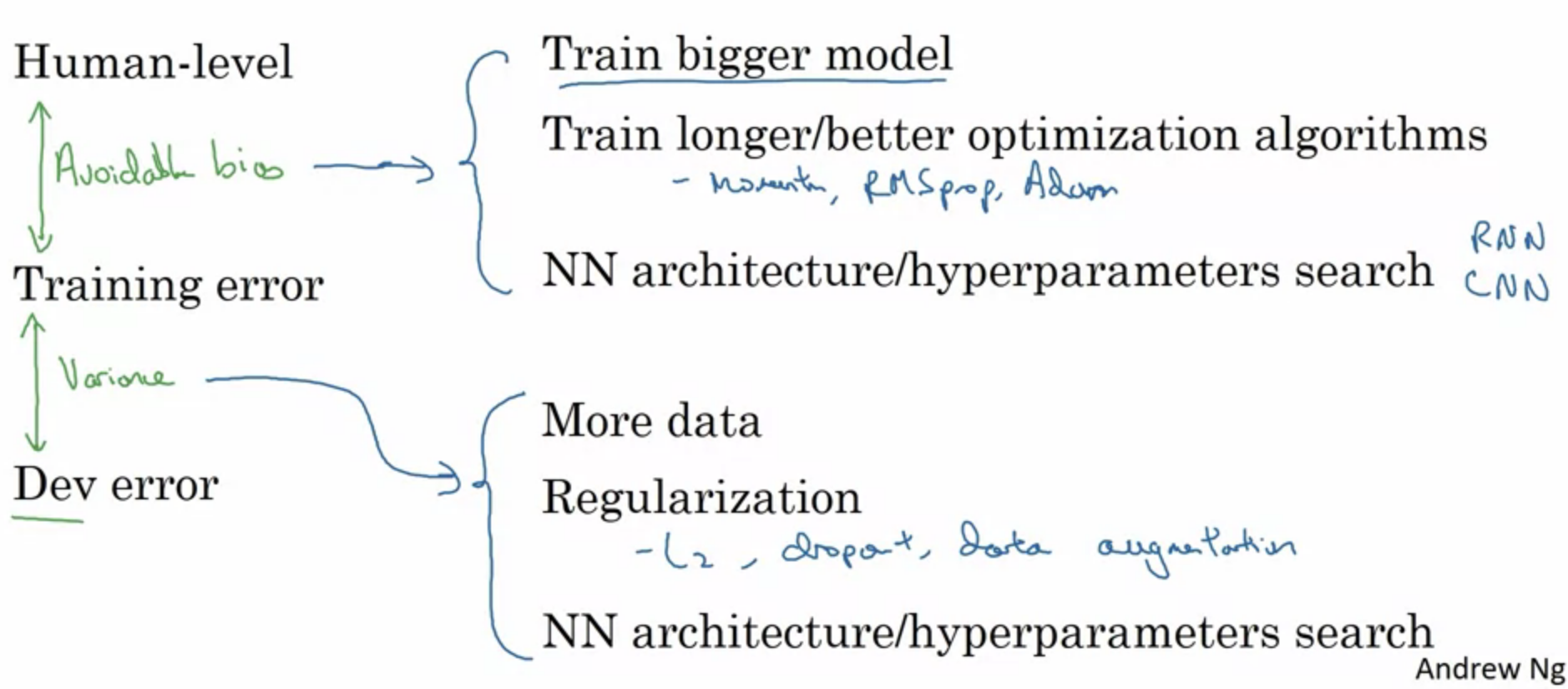
Improving your model performance
The two fundamental assumptions of supervised learning
- You can fit the training set pretty well
- The training set performance generalizes pretty well to the dev/test set
Error analysis
- Get ~100 mislabelled dev set examples
- Count up how many are dogs
- Ceiling
- Evaluate multiple ideas in parallel
eg. Ideas for cat detection
- Fix pictures of dogs being recognized as cats
- Fix great cats (lions, panthers, etc…) being misrecognized
- Improve performance on blurry images
Cleaning up incorrectly labelled data
DL algorithms are quite robust to random errors (eg. systematic errors) in the training set.
| Error type | Proposition |
|---|---|
| Overall dev set error | 10% |
| Errors due to incorrect labels | 0.6% |
| Errors due to other causes | 9.4% |
eg. Goal of dev set is to help you select between two classifiers A&B
If you don’t trust your dev set anymore to be correctly telling you whether this classifier is better than this because 0.6% of these mistakes are due to incorrect labels. Then there’s a good reason to go in and fix the incorrect labels in your dev set.
Correcting incorrect dev/test set examples
- Apply the same process to your dev and test sets to make sure they continue to come from the same distribution
- Consider examining examples your algorithm got right as well as ones it got wrong
- Train and dev/test data may now come from slightly different distributions
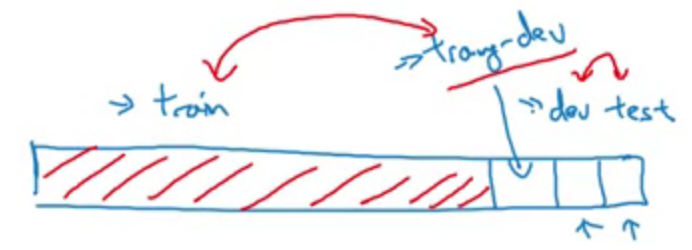
Mismatched training and dev/test set
Bias and variance with mismatched data distributions.
Training-dev set: same distribution as a training set, but not used for training.
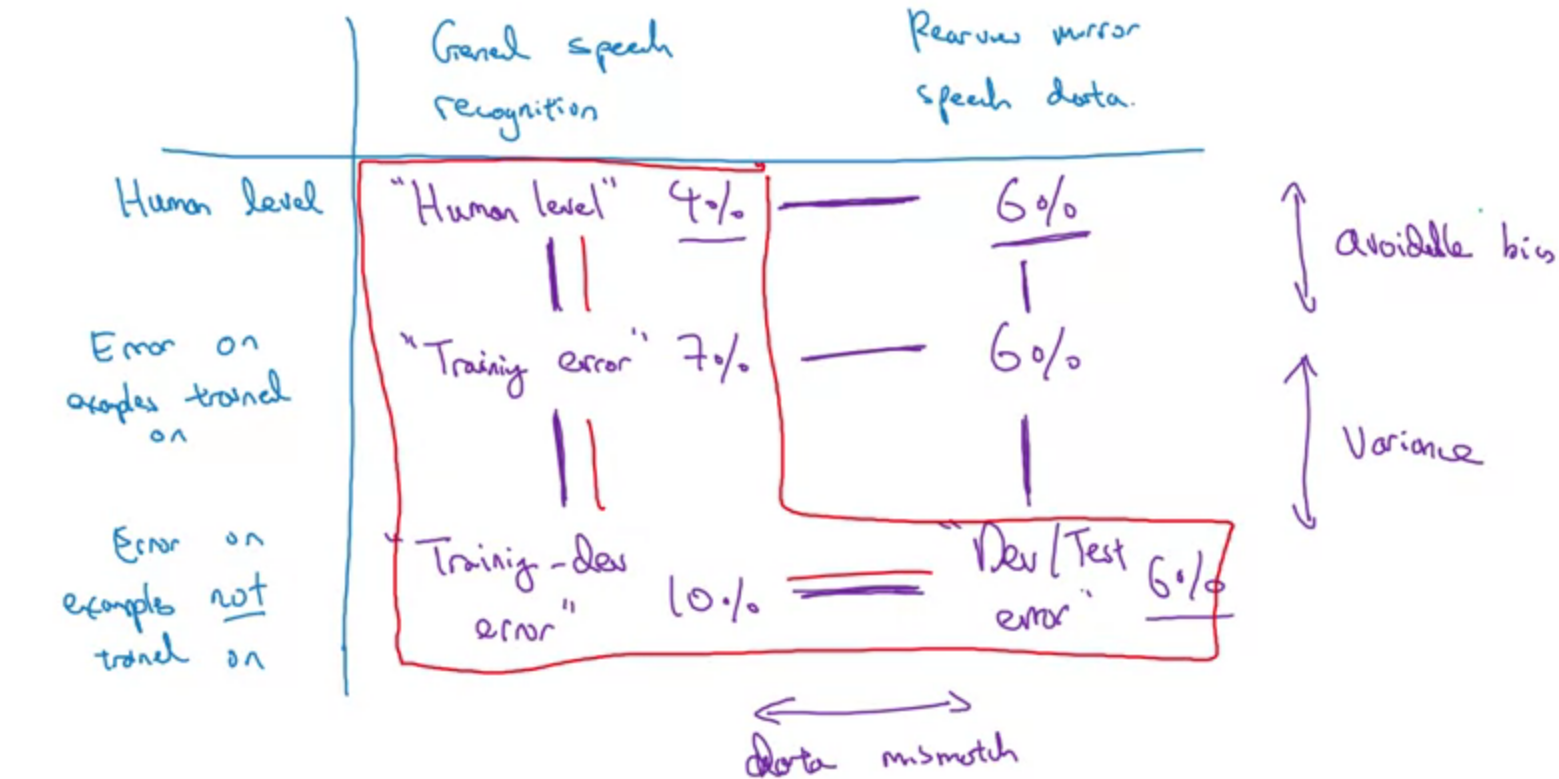
More general formulation
For human error, the way you get this number is you ask some humans to label their rear-view mirror speech data and just measure how good humans are at this task.
For training error, you can take some rear-view mirror speech data, put it in the training set so the neural networks learn on it as well, and then measure the error on that subset of the data.
Addressing data mismatch
- Carry out manual error analysis to try to understand the difference between training and dev/test sets (eg. noisy - car noise)
- Make training data more similar; or collect more data similar to dev/test sets
- Artificial data synthesis
Problem:

Reference
[1] Deeplearning.ai, Improving Deep Neural Networks: Hyperparameter Tuning, Regularization and Optimization
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!