Learning from Multiple Tasks - Class Review
Last updated on:3 years ago
And sometimes, you may be bothered by the small dataset and the high cost to enlarge it. In some cases, you have to consider several classes within each data. Fortunately, there are some practical methods we can use to deal with these problems.
Transfer learning
The ability of a system to recognize and apply knowledge and skills learned in previous tasks to novel tasks.
The model of transfer learning is first pre-trained on a data-rich task before being fine tuned on a downstream task.
eg.
Pre-training, 1,000,000, image recognition
Fine-tuning, 100, radiology diagnosis
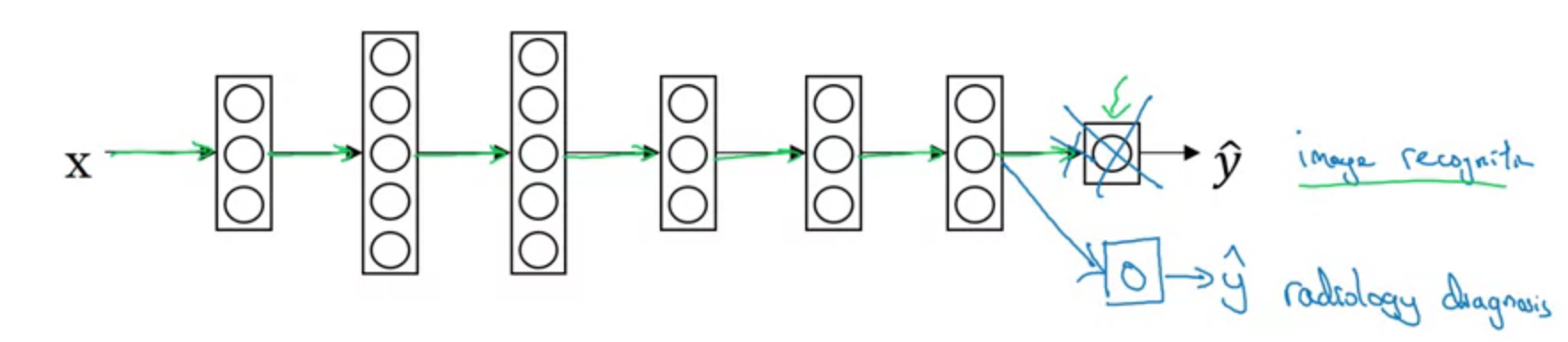
When transfer learning make sense
eg. Transfer from $A \to B$
Task A and B have the same input x
You have a lot more data for task A than task B
Low-level features from A could be helpful for learning B
Multi-task learning
Multi-task learning (MTL) is a learning paradigm in machine learning, aims to jointly learn multiple related tasks so that the knowledge contained in a task can be leveraged by other tasks with the hope of improving the generalization performance of all the tasks at hand.
eg. Simplified autonomous driving example.
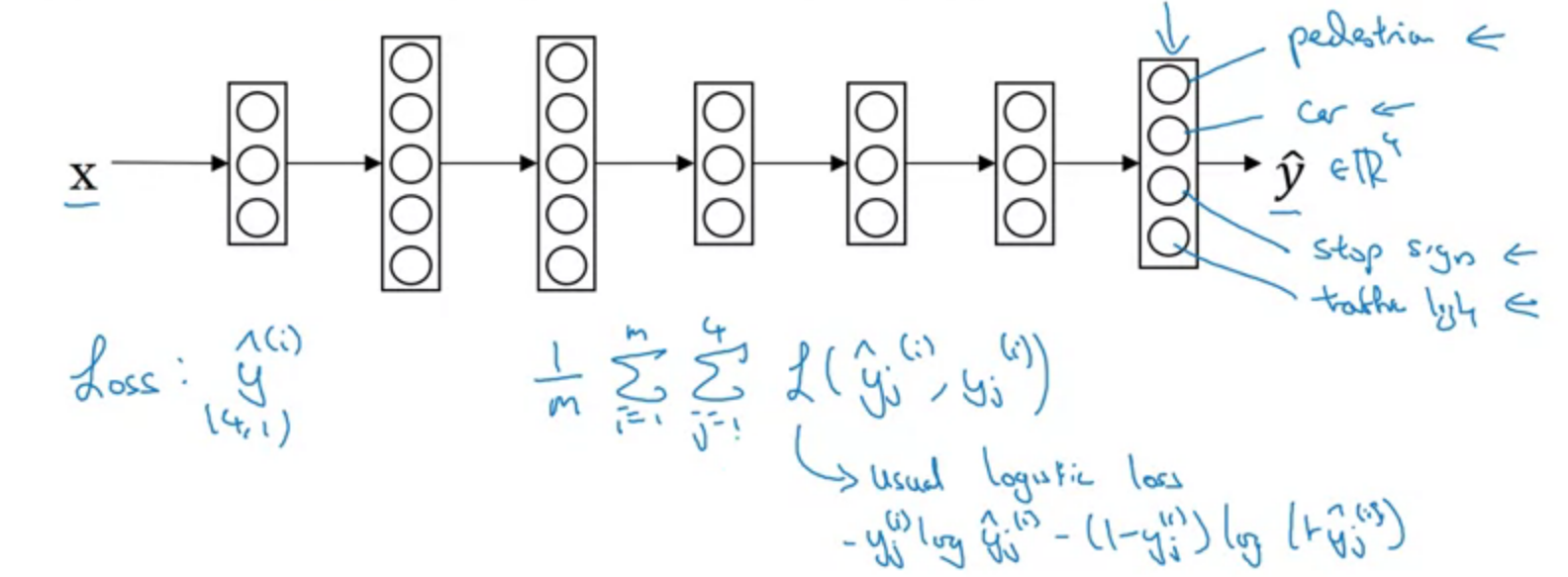
Unlike softmax regression: One image has multiple labels.
Sum only over the value of j with 0/1 label.
When multi-task learning makes sense
- Training on a set of tasks that could benefit from having shared lower-level features
- Usually: the amount of data you have for each task is quite similar
- Can train a big enough neural network to do well on all the tasks
End-to-end deep learning
The term end-to-end learning is used to refer to processing architectures where the entire stack, connecting the input to the desired output, is learned from data.
An end-to-end learning approach greatly reduces the need for prior knowledge about the problem and minimizes the required engineering effort.
Have data for each of the 2 sub-tasks.
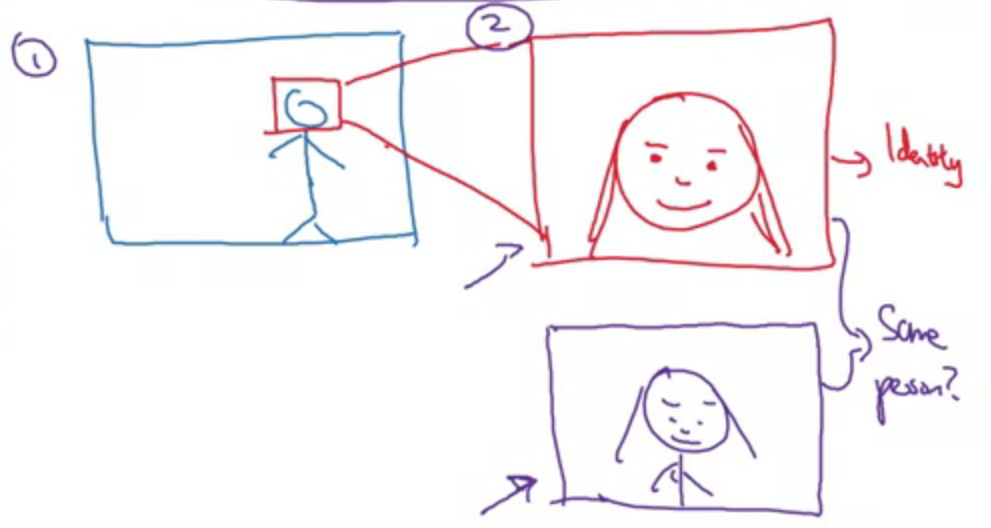
The example end to end is not good enough today, because we don’t have enough data (image - age).

When end-to-end deep learning makes sense
Pros and cons
Pros:
- Let the data speak
- Less hand-designing of components needed
Cons:
- May need a large amount of data
- Excludes potentially useful hand-designed components
Key question: Do you have sufficient data to learn a function of the complexity needed to map x to y?

- Use DL to learn individual components
- Carefully choose X \to Y depending on what task you can get data for
- Less promising: image $\to$ steering
Reference
[1] Deeplearning.ai, Improving Deep Neural Networks: Hyperparameter Tuning, Regularization and Optimization
[2] Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W. and Liu, P.J., 2019. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv preprint arXiv:1910.10683.
[3] Pan, S.J. and Yang, Q., 2009. A survey on transfer learning. IEEE Transactions on knowledge and data engineering, 22(10), pp.1345-1359.
[4] Zhang, Y. and Yang, Q., 2021. A survey on multi-task learning. IEEE Transactions on Knowledge and Data Engineering.
[5] Dieleman, S. and Schrauwen, B., 2014, May. End-to-end learning for music audio. In 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 6964-6968). IEEE.
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!