How to implement multi-GPU training with data parallel?
Last updated on:7 months ago
Introduction
A single-graphic processing unit (GPU) training is versatile and pratical.
However, it might not be workable when the model is comparatively large and consumes the GPU memory that exceed the limits.
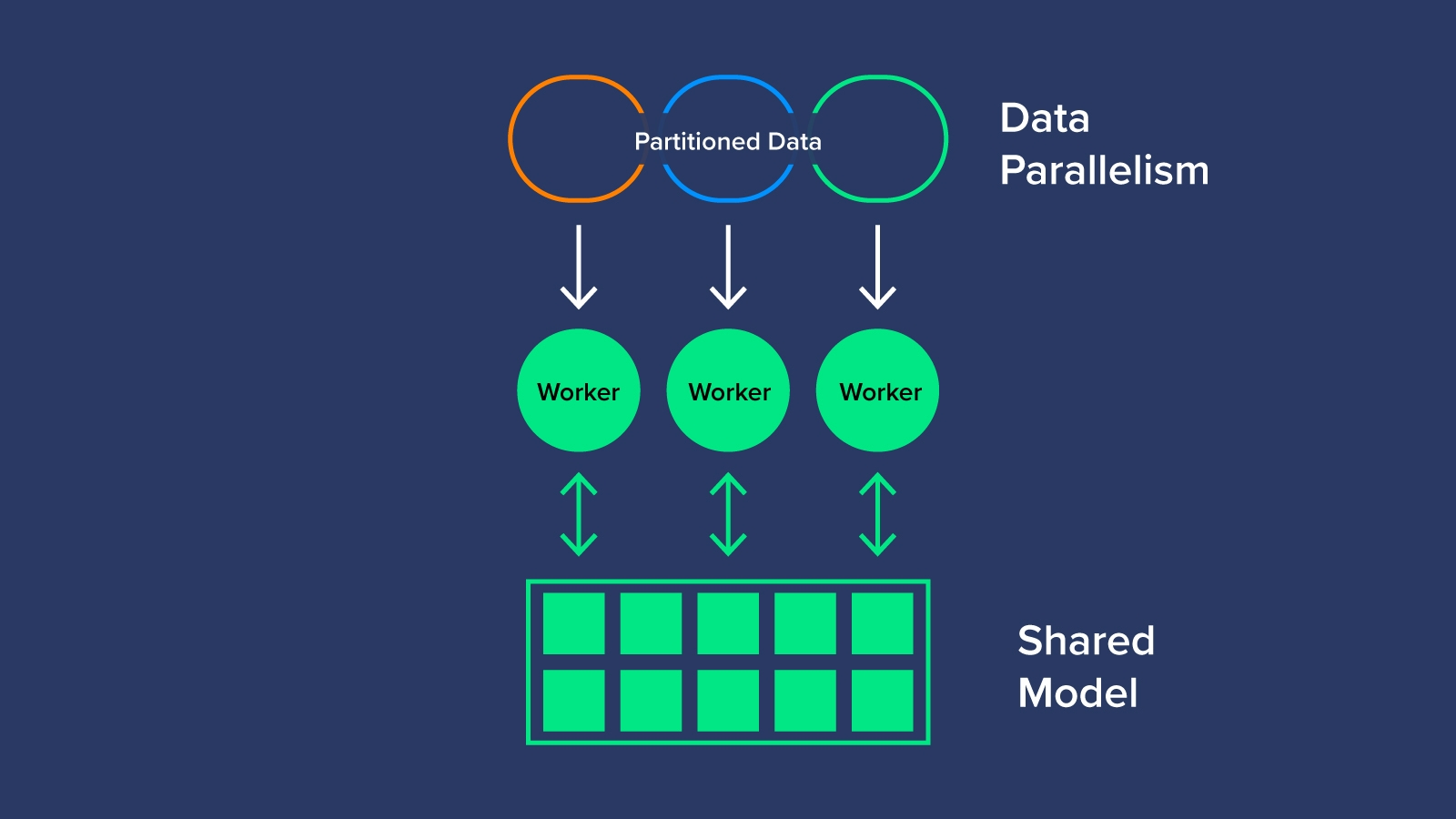
In such situations, we will use multiple-GPU training by partitioning the data into different GPU.
Data parallelism is a widely adopted single-program multiple-data training paradigm where the model is replicated on every process. Every model replica computes local gradients for a different set of input data samples. Gradients are averaged within the data-parallel communicator group before each optimizer step.
Model parallelism techniques (or Sharded data parallelism) are required when a model doesn’t fit in GPU, and can be combined together to form multi-dimensional (N-D) parallelism techniques.
Local rank vs rank
In the context of multi-node training, you have:
- local_rank, the rank of the process on the local machine (specific gpu).
- rank, the rank of the process in the network.
To illustrate that, let;s say you have 2 nodes (machines) with 2 GPU each, you will have a total of 4 processes (p1…p4):
| Node1 | Node2 | |||
|---|---|---|---|---|
| __ | p1 | p2 | p3 | p4 |
| local_rank | 0 | 1 | 0 | 1 |
| rank | 0 | 1 | 2 | 4 |
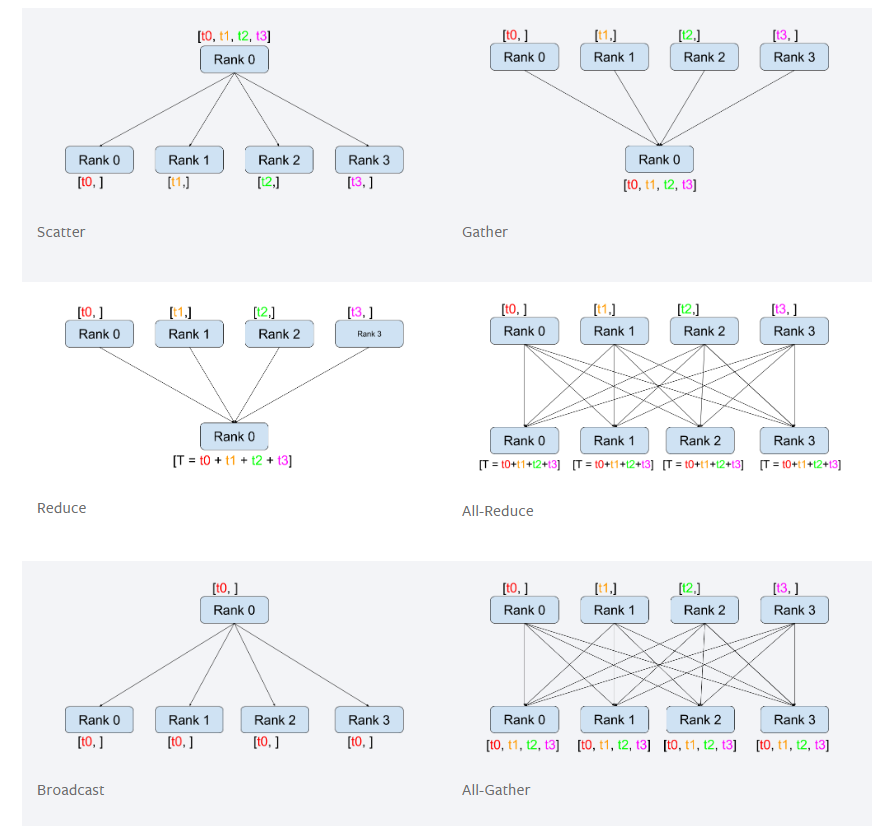
Tensor all reduce communication
All reduce allows all ranks in the network to share their variables.
Implementation
Multi-GPU framework adapted from single-GPU frame work
Distributed main function design, data loader design, move model into distributed environment, calculating metrics by gathering results from different GPUs through redution.
Application situation
- Use DistributedDataParallel (DDP), if your model fits in a single GPU but you want to easily scale up training using multiple GPUs.
- Use torchrun, to launch multiple pytorch processes if you are you using more than one node.
- See also: Getting Started with Distributed Data Parallel
- Use FullyShardedDataParallel (FSDP) when your model cannot fit on one GPU.
- See also: Getting Started with FSDP
- Use Tensor Parallel (TP) and/or Pipeline Parallel (PP) if you reach scaling limitations with FSDP.
Bugs
nccl stuck but gloo works
The NCCL_P2P_DISABLE variable disables the peer to peer (P2P) transport, which uses CUDA direct access between GPUs, using NVLink or PCI.
Links
Tutorial links
https://pytorch.org/tutorials/beginner/basics/quickstart_tutorial.html
https://pytorch.org/tutorials/beginner/ddp_series_theory.html
https://pytorch.org/tutorials/beginner/ddp_series_multigpu.html
https://pytorch.org/tutorials/beginner/former_torchies/parallelism_tutorial.html
https://huggingface.co/docs/transformers/en/perf_train_gpu_many
Reference links
https://pytorch.org/tutorials/beginner/dist_overview.html
https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/env.html#nccl-p2p-disable
https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/env.html
https://discuss.pytorch.org/t/what-is-the-difference-between-rank-and-local-rank/61940
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!