Multimodal in deep learning
Last updated on:3 years ago
Mountains of forms can represent information. For instance, someone who has a headache can be shown by medical instruction text, CT, face expression image, body temperature, etc. With some of this combination, we can increase the performance of our deep learning models.
Definition
Multimodality is the application of multiple literacies within one medium.
Multimodal image matching refers to identifying and then corresponding the same or similar true/content from two or more images that are significant modalities or nonlinear appearance differences.
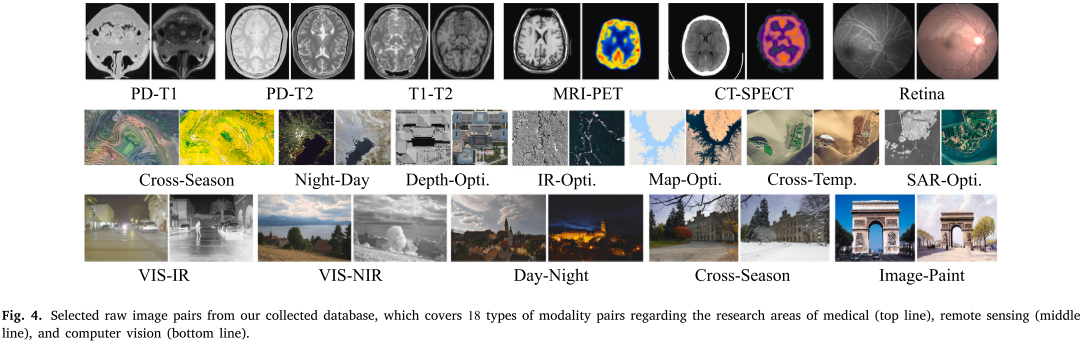
Multimodal analysis for biomedical applications:
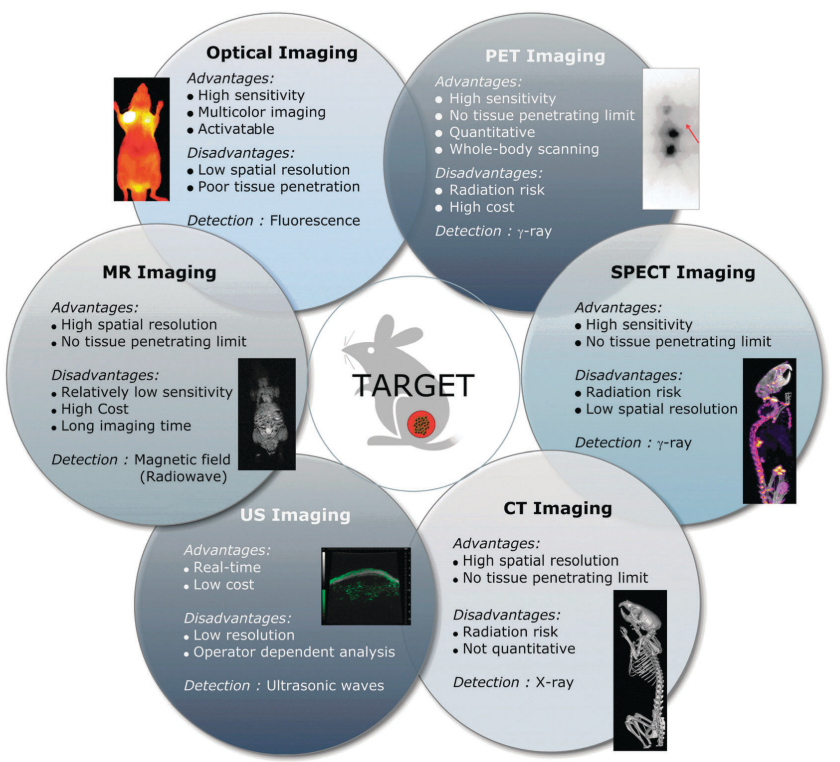
Research in deep learning
Some researches focus on aligning the information of different modals. In Amazon research works in vision-language representation learning, image information and text information are aligned to increase the performance by cross-modality fusion. You can see this in the following picture.
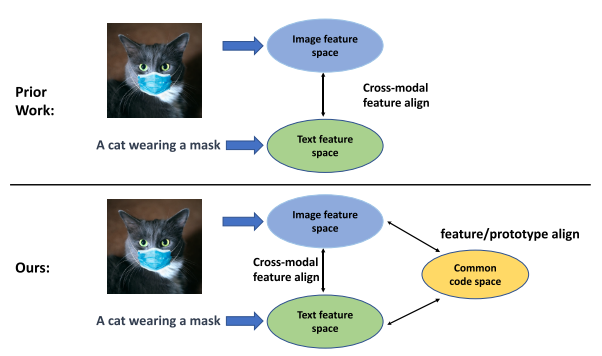
You can also carefully design your network to simultaneously feed multimodal data into the network.
Others
简单来说,multi-view一般指同一个对象不同的表现形式。比如一个3D物体不同角度或者不同频谱下的成像图像。multimodality指不同模态,它们所表现的可能是不同的对象,但之间有联系。比如文本和对应的音视频。这两者之间最关键的区别是后者可能不是描述完全一样的物体或对象,所以往往需要有个预对齐或者建立两者间的对应关系,既correspondence
Reference
[1] Multimodality, wiki
[2] Jiang, X., Ma, J., Xiao, G., Shao, Z. and Guo, X., 2021. A review of multimodal image matching: Methods and applications. Information Fusion, 73, pp.22-71.https://www.coursera.org/learn/deep-neural-network)
[3] Duan, J., Chen, L., Tran, S., Yang, J., Xu, Y., Zeng, B., Tao, C. and Chilimbi, T., 2022. Multi-modal Alignment using Representation Codebook. arXiv preprint arXiv:2203.00048.
[4] Lee, D.E., Koo, H., Sun, I.C., Ryu, J.H., Kim, K. and Kwon, I.C., 2012. Multifunctional nanoparticles for multimodal imaging and theragnosis. Chemical Society Reviews, 41(7), pp.2656-2672.
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!