My journey to transformer
Last updated on:2 years ago
The Transformer is a new era of deep learning handling images and videos. Compared to convolution, it is relatively small but maintains relatively high performance.
Transformer
Background
- RNN has a vanishing gradient
- LSTM: use gates to control the gate of information
All of them has a few more computation.
Self-attention: e.g. computing all the words in sentences in parallel (Multiheads)
Transformers attention
$A(q, K, V)$ = attention-based vector representation of a word.
$$A(q, K, V) = \sum_i \frac{\text{exp} (q\cdot k^{< i >})}{\text{exp} (q\cdot k^{< j >})} v^{< i >}$$
Q: Query, what’s happening there?
K: Key, What’s the relevant answer to that case?
V: Value, allows the representation to the plugin.
The goal of this operation is to pull up the most information that’s needed to help us compute the most helpful representation $A^{< 3 >}$ up here.
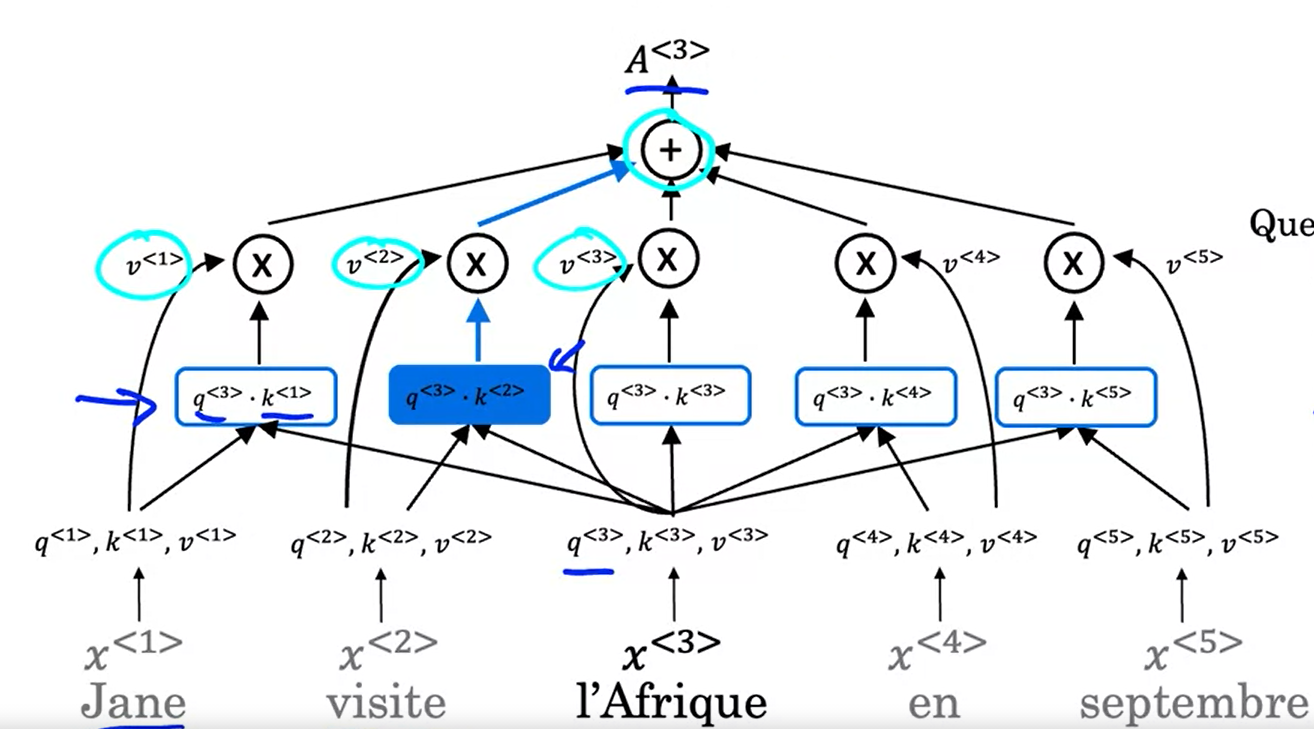
$$\text{Attention} (Q, K, V) = \text{softmax} (\frac{QK^T}{\sqrt{d_k}}) V$$
Embeddings and softmax
We apply embeddings to convert the input tokens and output tokens to vectors of dimension $d_ {\text{model}}$. To facilitate these residual connections, all sub-layers in the model, as well as the embedding layers, produce outputs of dimension $d_ \text{model} = 512$
The input data of sequence is [len, batch size] shape tensor. After embedding, it would be [len, batchsize, emb_size] shape tensor. emb_size means $d$ in positional encoding.
Code:
class TokenEmbedding(nn.Module):
def __init__(self, vocab_size: int, emb_size):
super(TokenEmbedding, self).__init__()
self.embedding = nn.Embedding(vocab_size, emb_size)
self.emb_size = emb_size
def forward(self, tokens: Tensor):
return self.embedding(tokens.long()) * math.sqrt(self.emb_size)Positional encoding
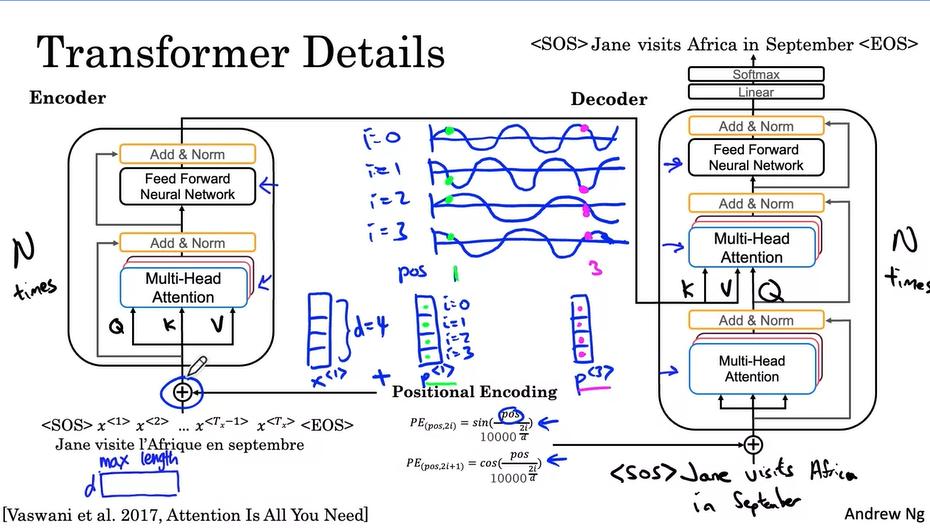
To make use of the order of sequence, we inject some information about the relative or absolute position of the tokens in the sequence (no recurrence and no convolution).
$$PE (pos, 2i) = sin(pos/10000^{2i/d_{\text{model}}})$$
$$PE (pos, 2i+1) = cos(pos/10000^{2i/d_{\text{model}}})$$
$d$ is the dimension of the word embedding and positional encoding, $pos$ is the position of the word, and $i$ refers to each of the different dimensions of the positional encoding. And $d$ must be divisible by $h$ (head No. ).
Code:
class PositionalEncoding(nn.Module):
def __init__(self,
emb_size: int,
dropout: float,
maxlen: int = 5000):
super(PositionalEncoding, self).__init__()
den = torch.exp(- torch.arange(0, emb_size, 2)* math.log(10000) / emb_size)
pos = torch.arange(0, maxlen).reshape(maxlen, 1)
pos_embedding = torch.zeros((maxlen, emb_size))
pos_embedding[:, 0::2] = torch.sin(pos * den)
pos_embedding[:, 1::2] = torch.cos(pos * den)
pos_embedding = pos_embedding.unsqueeze(-2)
self.dropout = nn.Dropout(dropout)
self.register_buffer('pos_embedding', pos_embedding)
def forward(self, token_embedding: Tensor):
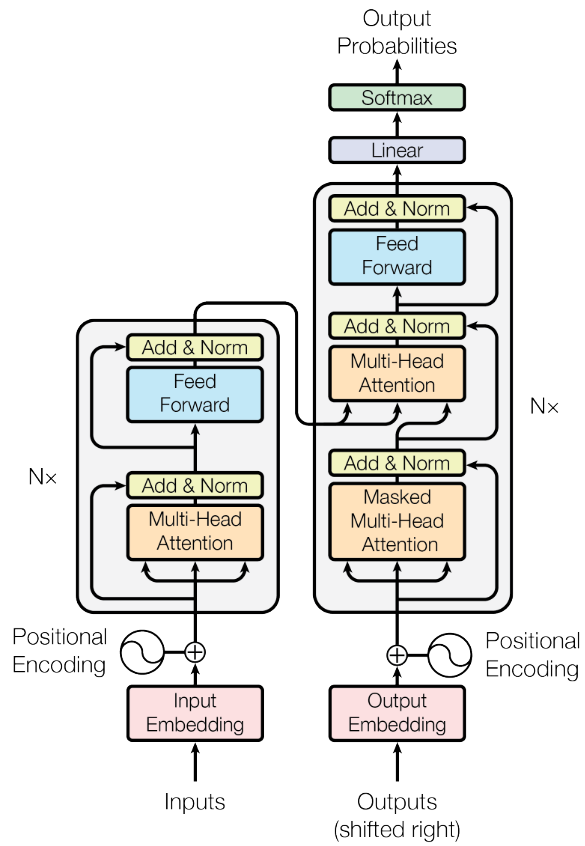
return self.dropout(token_embedding + self.pos_embedding[:token_embedding.size(0), :])Encoder - decoder
The encoder maps an input sequence of symbol representations $(x_1, …, x_n)$ to a sequence of continuous representations $z = (z_1, …, z_n)$. Given $z$, the decoder then generates an output sequence $(y_1, …, y_m)$ of symbols one element at a time.
N: number of identical layers. A residual connection is utilized around each of the two sub-layer, follow by layer normalization. $\text{LayerNorm} (x + \text{Sublayer} (x))$.
Code:
def _get_clones(module, N):
return ModuleList([copy.deepcopy(module) for i in range(N)])Encoder: repeated N times
The Transformer encoder layer pairs self-attention and convolutional neural network style of processing to improve the speed of training and passes $K$ and $V$ matrices to the decoder.
class TransformerEncoder(Module):
__constants__ = ['norm']
def __init__(self, encoder_layer, num_layers, norm=None):
super(TransformerEncoder, self).__init__()
self.layers = _get_clones(encoder_layer, num_layers)
self.num_layers = num_layers
self.norm = norm
def forward(self, src: Tensor, mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None) -> Tensor:
output = src
for mod in self.layers:
output = mod(output, src_mask=mask, src_key_padding_mask=src_key_padding_mask)
if self.norm is not None:
output = self.norm(output)
return output
Decoder: repeated N times
Predict the next words in the sentence.
class TransformerDecoder(Module):
__constants__ = ['norm']
def __init__(self, decoder_layer, num_layers, norm=None):
super(TransformerDecoder, self).__init__()
self.layers = _get_clones(decoder_layer, num_layers)
self.num_layers = num_layers
self.norm = norm
def forward(self, tgt: Tensor, memory: Tensor, tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None, tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None) -> Tensor:
output = tgt
for mod in self.layers:
output = mod(output, memory, tgt_mask=tgt_mask,
memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask)
if self.norm is not None:
output = self.norm(output)
return outputHowever, when you train a Transformer network using multi-head attention, you feed your data into the model all at once. While this dramatically reduces training time, there is no information about the order of your data. That is why positional encoding is proper - you can specifically encode the positions of your inputs and pass them into the network using these sine and cosine formulas.
Code:
from torch.nn import Transformer
class TransformerEncoderLayer(Module):
__constants__ = ['batch_first', 'norm_first']
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1, activation=F.relu,
layer_norm_eps=1e-5, batch_first=False, norm_first=False,
device=None, dtype=None) -> None:
factory_kwargs = {'device': device, 'dtype': dtype}
super(TransformerEncoderLayer, self).__init__()
self.self_attn = MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=batch_first,
**factory_kwargs)
# Implementation of Feedforward model
self.linear1 = Linear(d_model, dim_feedforward, **factory_kwargs)
self.dropout = Dropout(dropout)
self.linear2 = Linear(dim_feedforward, d_model, **factory_kwargs)
self.norm_first = norm_first
self.norm1 = LayerNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
self.norm2 = LayerNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
self.dropout1 = Dropout(dropout)
self.dropout2 = Dropout(dropout)
# Legacy string support for activation function.
if isinstance(activation, str):
self.activation = _get_activation_fn(activation)
else:
self.activation = activation
def __setstate__(self, state):
if 'activation' not in state:
state['activation'] = F.relu
super(TransformerEncoderLayer, self).__setstate__(state)
def forward(self, src: Tensor, src_mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None) -> Tensor:
x = src
if self.norm_first:
x = x + self._sa_block(self.norm1(x), src_mask, src_key_padding_mask)
x = x + self._ff_block(self.norm2(x))
else:
x = self.norm1(x + self._sa_block(x, src_mask, src_key_padding_mask)) # self-attention(multihead) + skip-connection
x = self.norm2(x + self._ff_block(x)) # Feedforward + skip-connection
return x
# self-attention block
def _sa_block(self, x: Tensor,
attn_mask: Optional[Tensor], key_padding_mask: Optional[Tensor]) -> Tensor:
x = self.self_attn(x, x, x,
attn_mask=attn_mask,
key_padding_mask=key_padding_mask,
need_weights=False)[0]
return self.dropout1(x)
# feed forward block
def _ff_block(self, x: Tensor) -> Tensor:
x = self.linear2(self.dropout(self.activation(self.linear1(x))))
return self.dropout2(x)q, k, v in encoder are input sequence. Input sequence shape won’t be changed after encoding.
class TransformerDecoderLayer(Module):
__constants__ = ['batch_first', 'norm_first']
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1, activation=F.relu,
layer_norm_eps=1e-5, batch_first=False, norm_first=False,
device=None, dtype=None) -> None:
factory_kwargs = {'device': device, 'dtype': dtype}
super(TransformerDecoderLayer, self).__init__()
self.self_attn = MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=batch_first,
**factory_kwargs)
self.multihead_attn = MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=batch_first,
**factory_kwargs)
# Implementation of Feedforward model
self.linear1 = Linear(d_model, dim_feedforward, **factory_kwargs)
self.dropout = Dropout(dropout)
self.linear2 = Linear(dim_feedforward, d_model, **factory_kwargs)
self.norm_first = norm_first
self.norm1 = LayerNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
self.norm2 = LayerNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
self.norm3 = LayerNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
self.dropout1 = Dropout(dropout)
self.dropout2 = Dropout(dropout)
self.dropout3 = Dropout(dropout)
# Legacy string support for activation function.
if isinstance(activation, str):
self.activation = _get_activation_fn(activation)
else:
self.activation = activation
def __setstate__(self, state):
if 'activation' not in state:
state['activation'] = F.relu
super(TransformerDecoderLayer, self).__setstate__(state)
def forward(self, tgt: Tensor, memory: Tensor, tgt_mask: Optional[Tensor] = None, memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None, memory_key_padding_mask: Optional[Tensor] = None) -> Tensor:
x = tgt
if self.norm_first:
x = x + self._sa_block(self.norm1(x), tgt_mask, tgt_key_padding_mask)
x = x + self._mha_block(self.norm2(x), memory, memory_mask, memory_key_padding_mask)
x = x + self._ff_block(self.norm3(x))
else:
x = self.norm1(x + self._sa_block(x, tgt_mask, tgt_key_padding_mask)) # self-attention(multihead) + skip-connection
x = self.norm2(x + self._mha_block(x, memory, memory_mask, memory_key_padding_mask)) # attention(multihead) + skip-connection
x = self.norm3(x + self._ff_block(x))
return x
# self-attention block
def _sa_block(self, x: Tensor,
attn_mask: Optional[Tensor], key_padding_mask: Optional[Tensor]) -> Tensor:
x = self.self_attn(x, x, x,
attn_mask=attn_mask,
key_padding_mask=key_padding_mask,
need_weights=False)[0]
return self.dropout1(x)
# multihead attention block
def _mha_block(self, x: Tensor, mem: Tensor,
attn_mask: Optional[Tensor], key_padding_mask: Optional[Tensor]) -> Tensor:
x = self.multihead_attn(x, mem, mem,
attn_mask=attn_mask,
key_padding_mask=key_padding_mask,
need_weights=False)[0]
return self.dropout2(x)
# feed forward block
def _ff_block(self, x: Tensor) -> Tensor:
x = self.linear2(self.dropout(self.activation(self.linear1(x))))
return self.dropout3(x)In the first multihead attention of the decoder, q, k, and v are target sequences** in the encoder.
In the second multihead attention of decoder,
q: target sequence $x’$ from the first attention module.
k: memory (encoder data)
v: memory (encoder data)
Both attention can use MultiheadAttention class.
Sequence to sequence
There are $N\times$ encoder identical layers and decoder layers. You can see it in the following images.
Code:
# Seq2Seq Network
class Seq2SeqTransformer(nn.Module):
def __init__(self,
num_encoder_layers: int,
num_decoder_layers: int,
emb_size: int,
nhead: int,
src_vocab_size: int,
tgt_vocab_size: int,
dim_feedforward: int = 512,
dropout: float = 0.1):
super(Seq2SeqTransformer, self).__init__()
self.transformer = Transformer(d_model=emb_size,
nhead=nhead,
num_encoder_layers=num_encoder_layers,
num_decoder_layers=num_decoder_layers,
dim_feedforward=dim_feedforward,
dropout=dropout)
self.generator = nn.Linear(emb_size, tgt_vocab_size)
self.src_tok_emb = TokenEmbedding(src_vocab_size, emb_size)
self.tgt_tok_emb = TokenEmbedding(tgt_vocab_size, emb_size)
self.positional_encoding = PositionalEncoding(
emb_size, dropout=dropout)
def forward(self,
src: Tensor,
trg: Tensor,
src_mask: Tensor,
tgt_mask: Tensor,
src_padding_mask: Tensor,
tgt_padding_mask: Tensor,
memory_key_padding_mask: Tensor):
src_emb = self.positional_encoding(self.src_tok_emb(src))
tgt_emb = self.positional_encoding(self.tgt_tok_emb(trg))
outs = self.transformer(src_emb, tgt_emb, src_mask, tgt_mask, None,
src_padding_mask, tgt_padding_mask, memory_key_padding_mask)
return self.generator(outs)
def encode(self, src: Tensor, src_mask: Tensor):
return self.transformer.encoder(self.positional_encoding(
self.src_tok_emb(src)), src_mask)
def decode(self, tgt: Tensor, memory: Tensor, tgt_mask: Tensor):
return self.transformer.decoder(self.positional_encoding(
self.tgt_tok_emb(tgt)), memory,
tgt_mask)Reference
[1] Deeplearning.ai, Sequence Models
[2] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł. and Polosukhin, I., 2017. Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008).
[3] A Survey on Vision Transformer
[4] Chen, M., Radford, A., Child, R., Wu, J., Jun, H., Luan, D. and Sutskever, I., 2020, November. Generative pretraining from pixels. In International Conference on Machine Learning (pp. 1691-1703). PMLR.
[5] Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S. and Uszkoreit, J., 2020. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929.
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!