Weakly supervised learning has various diversities of labels
Last updated on:4 months ago
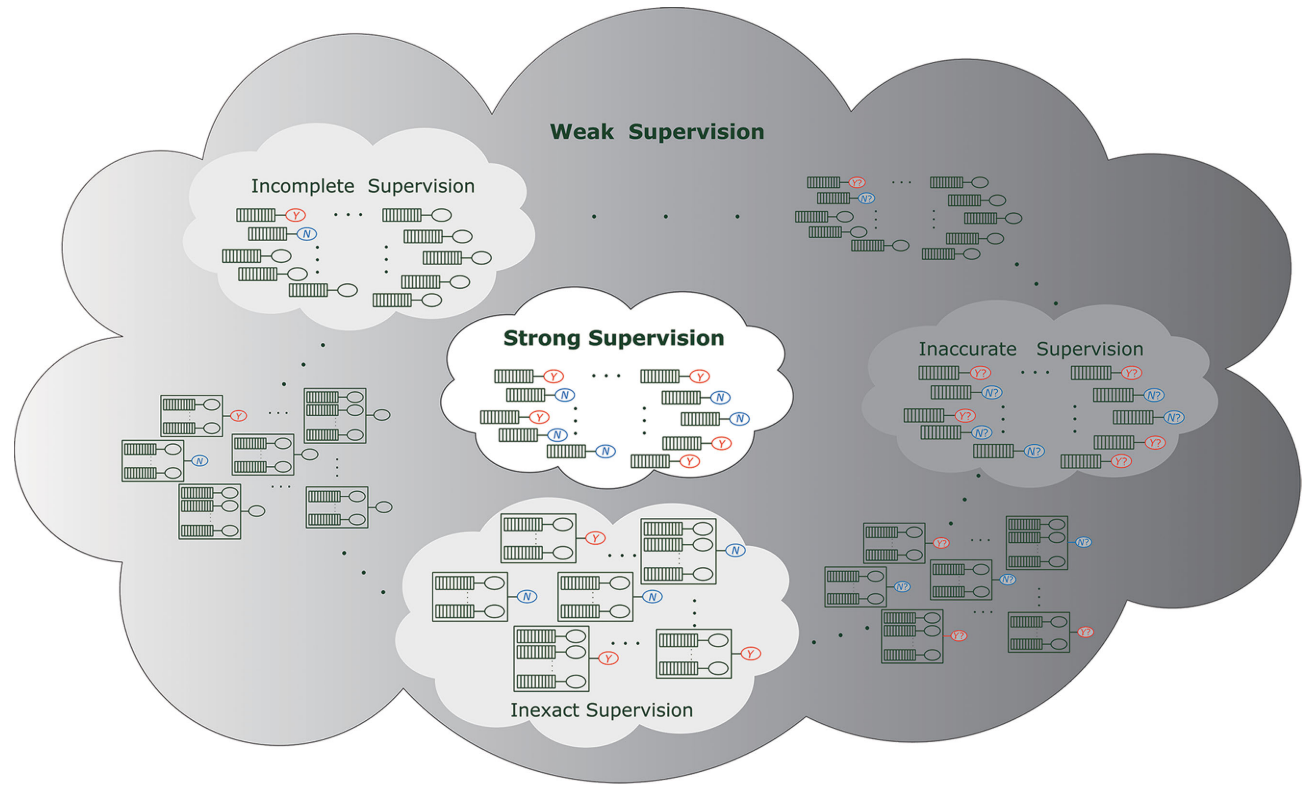
Weak supervision has three types: incomplete supervision, inexact supervision, and inaccurate supervision. Weakly supervised learning is generally defined as a learning framework under inadequate supervision. However, I argue that weakly supervised learning is only using inexact supervision.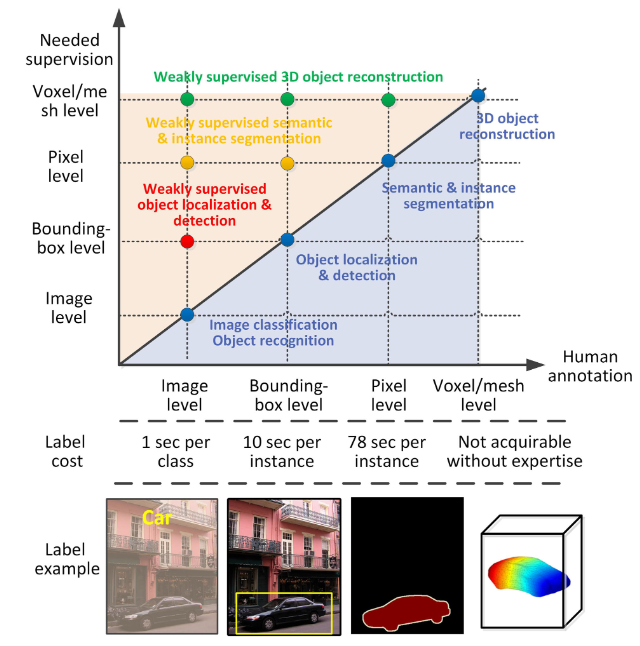
Introduction
Weakly supervised learning is a machine learning framework where the model is trained using examples that are only partially annotated or labelled.
Weak supervision types
The majority of research works about weakly supervision means inexact supervision. Here, I assume that weakly supervised learning only has inexact supervision.
Incomplete supervision concerns the situation in which we are given a small amount of labelled data, which is insufficient to train a good learner, while abundant unlabelled data are available. Two primary techniques for incomplete supervision are active learning and semi-supervised learning. Only a subset of training data is given with labels.
Inexact supervision concerns the situation in which some supervision information is given but not as exact as desired. A typical scenario is when only coarse-grained label information is available. The training data are given with only coarse-grained labels.
Inaccurate supervision concerns the situation in which the supervision information is not always ground-truth; in other words, some label information may suffer from errors. The given labels are not always ground-truth.
Motivation
- Challenging to get strong supervision information like fully ground-truth labels.
- The high cost of the data-labelling process.
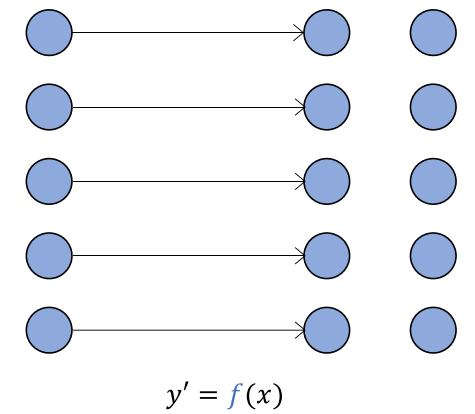
From the data point of view
Data in both input $x$ and output $y$ with known mapping for $y$
(Learn the mapping $f$ for another output $y^{‘}$)
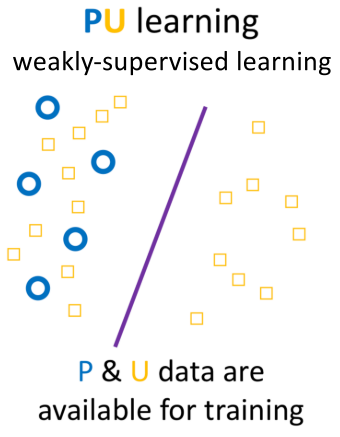
PU learning, P: positive data, U: unlabelled data
Safety
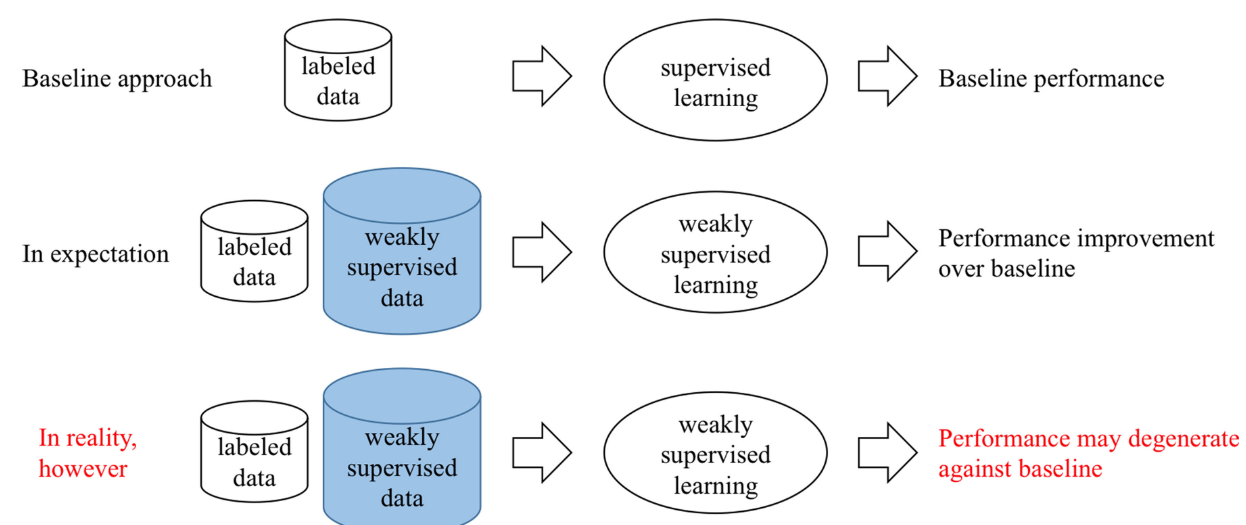
In practice, weakly supervised learning may not be safe, i.e. it may degenerate the performance with the usage of weakly supervised data.
Application
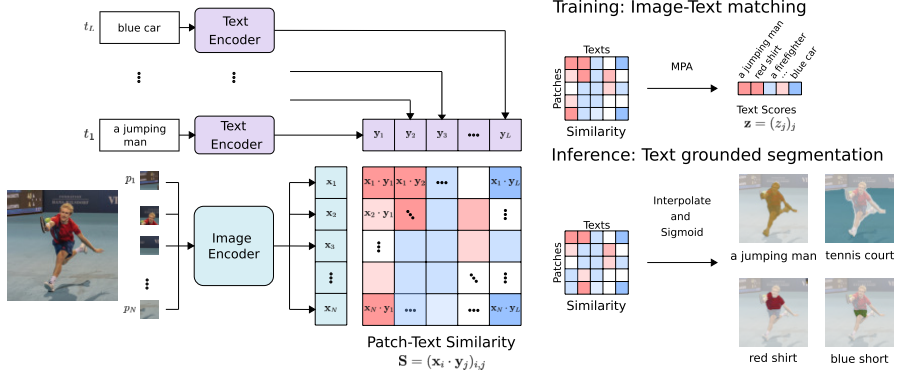
Learn segmentation via text
Given an image and a set of referring expressions, such as “a man sitting on the grass and a wooden stairway“, TSEG segments the image regions corresponding to the input expressions.

Image patches and referring expressions are mapped with transformers to patch and text embeddings and then compared by computing the patch-text cosine similarity score.
Learn localization via classification
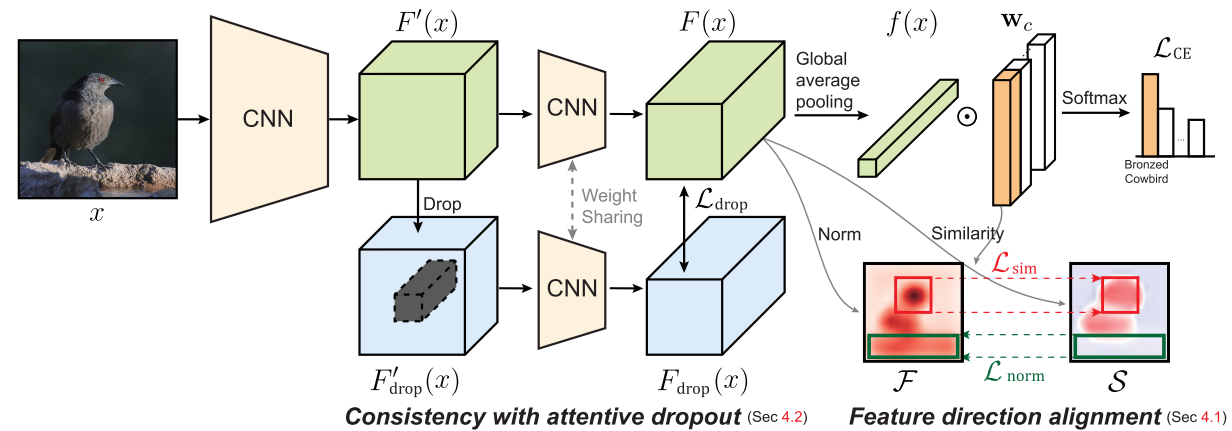
Weakly supervised object localization aims to find a target object region in a given image with only weak supervision, such as image-level labels.
Kim et al. align feature directions with a class-specific weight in object localization.
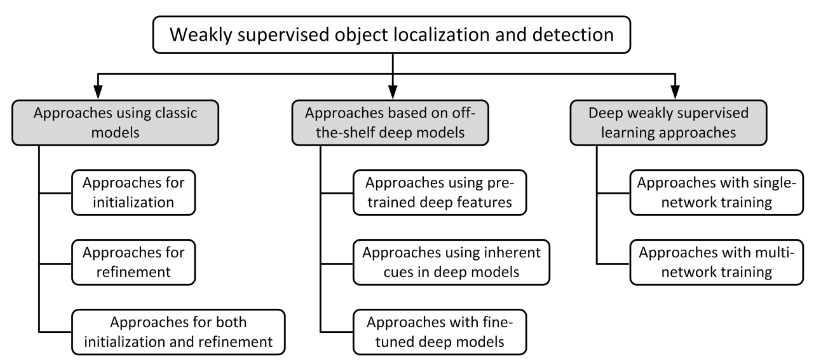
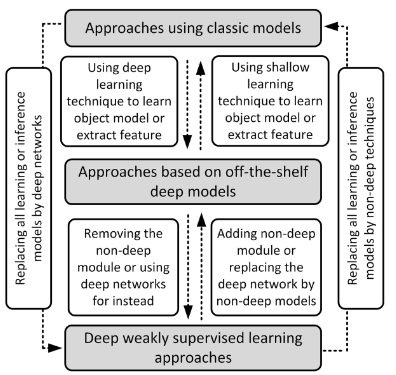
The taxonomy of the existing approaches for weakly supervised object localisation and detection.
The relationship among the approaches in different categories.
Learn localization via visual relations
Only image-level supervision is given to learning to detect ad localize relations between objects.
For instance, the following image is associated with a caption: “A person falling off the side of a horse as it rides”. The boxes correspond to the possible candidates for object category person (blue) and horse (red).

Reference
[1] Zhou, Z.H., 2018. A brief introduction to weakly supervised learning. National science review, 5(1), pp.44-53.
[2] Hao Dong, Learning Methods.
[3] Kim, E., Kim, S., Lee, J., Kim, H. and Yoon, S., 2022. Bridging the Gap between Classification and Localization for Weakly Supervised Object Localization. arXiv preprint arXiv:2204.00220.
[4] Strudel, R., Laptev, I. and Schmid, C., 2022. Weakly-supervised segmentation of referring expressions. arXiv preprint arXiv:2205.04725.
[5] Peyre, J., Sivic, J., Laptev, I. and Schmid, C., 2017. Weakly-supervised learning of visual relations. In Proceedings of the ieee international conference on computer vision (pp. 5179-5188).
[6] Zhang, D., Han, J., Cheng, G. and Yang, M.H., 2021. Weakly supervised object localization and detection: A survey. IEEE transactions on pattern analysis and machine intelligence.
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!