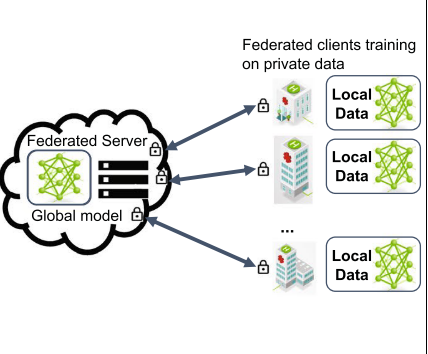
One server can collaborate with global clients using federated learning
Last updated on:3 years ago
Live data of humans and other natural mechanisms are constantly generated every day. With the development of human living standards and perceptron, new types of data will be updated. Thus, there is a tremendous need to analyse these new data swiftly and effectively. Federated learning was born to satisfy these requirements and maybe become the most demanding deep learning research field in the future.
Introduction
Federated learning means leaving the training data distributed on the mobile devices and learning a shared model by aggregating locally-computed updates.
Federate learning (also known as collaborative learning) is a machine learning technique that trains an algorithm across multiple decentralised edge devices or servers holding local data samples without exchanging them. This approach stands in contrast to traditional centralised machine learning techniques where all the local datasets are uploaded to one server and more classical decentralised methods that often assume that local data samples are identically distributed.

Federated learning is a machine learning setting where the goal is to train a high-quality centralised model. At the same time, training data remains distributed over a large number of clients, each with unreliable and relatively slow network connections.
Federated learning enables mobile phones to collaboratively learn a shared prediction model while keeping all the training data on devices, decoupling the ability to do machine learning from the need to store the data in the cloud. The learning task is solved by a loose federation of participating devices (clients) coordinated by a central server.
Motivation
- Mobile devices have access to an unprecedented amount of data.
- Undirect access to the raw training data.
Non-IID (non-identically independently distributed): the training data on a given client is typically based on the mobile device usage by a particular user. Hence, any specific user’s local dataset will not represent the population distribution.
- The risks of privacy and security of the cloud.
Characteristics
- A considerable number of clients.
Massively distributed: the number of clients participating in optimisation to be much larger than the average number of examples per client.
- Highly unbalanced and non-i.i.d. data available on each client.
Unbalanced: similarly, some users will make much heavier use of the service or app than others, leading to varying local training data.
- Relatively poor network connections.
Limited communication: Mobile devices are frequently offline or on slow or expensive connections.
- Naïve: each client sends a full model (or an entire model update) back to the server in each round.
Steps
- A subset of existing clients is selected, each of which downloads the current model.
- Each client in the subset computes an updated model based on their local data.
- The model updates are sent from the selected clients to the server.
- The server aggregates these models (typically by averaging) to construct an improved global model.
Federated averaging algorithm
It combines local stochastic gradient descent (SGD) with a server that performs model averaging on each client.

Codes
LocalUpdate(), update_weights using global model weight.
def update_weights(self, model, global_round):
# Set mode to train model
model.train()
epoch_loss = []
# Set optimizer for the local updates
if self.args.optimizer == 'sgd':
optimizer = torch.optim.SGD(model.parameters(), lr=self.args.lr,
momentum=0.5)
elif self.args.optimizer == 'adam':
optimizer = torch.optim.Adam(model.parameters(), lr=self.args.lr,
weight_decay=1e-4)
for iter in range(self.args.local_ep):
batch_loss = []
for batch_idx, (images, labels) in enumerate(self.trainloader):
images, labels = images.to(self.device), labels.to(self.device)
model.zero_grad()
log_probs = model(images)
loss = self.criterion(log_probs, labels)
loss.backward()
optimizer.step()
if self.args.verbose and (batch_idx % 10 == 0):
print('| Global Round : {} | Local Epoch : {} | [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
global_round, iter, batch_idx * len(images),
len(self.trainloader.dataset),
100. * batch_idx / len(self.trainloader), loss.item()))
self.logger.add_scalar('loss', loss.item())
batch_loss.append(loss.item())
epoch_loss.append(sum(batch_loss)/len(batch_loss))
return model.state_dict(), sum(epoch_loss) / len(epoch_loss)The server weights and loss of training are updated by:
# update global weights
global_weights = average_weights(local_weights)
# update global weights
global_model.load_state_dict(global_weights)
loss_avg = sum(local_losses) / len(local_losses)Training codes for each epoch:
local_weights, local_losses = [], []
print(f'\n | Global Training Round : {epoch+1} |\n')
global_model.train()
m = max(int(args.frac * args.num_users), 1)
idxs_users = np.random.choice(range(args.num_users), m, replace=False)
for idx in idxs_users:
local_model = LocalUpdate(args=args, dataset=train_dataset,
idxs=user_groups[idx], logger=logger)
w, loss = local_model.update_weights(
model=copy.deepcopy(global_model), global_round=epoch)
local_weights.append(copy.deepcopy(w))
local_losses.append(copy.deepcopy(loss))
# update global weights
global_weights = average_weights(local_weights)
# update global weights
global_model.load_state_dict(global_weights)
loss_avg = sum(local_losses) / len(local_losses)
train_loss.append(loss_avg)
# Calculate avg training accuracy over all users at every epoch
list_acc, list_loss = [], []
global_model.eval()
for c in range(args.num_users):
local_model = LocalUpdate(args=args, dataset=train_dataset,
idxs=user_groups[idx], logger=logger)
acc, loss = local_model.inference(model=global_model)
list_acc.append(acc)
list_loss.append(loss)
train_accuracy.append(sum(list_acc)/len(list_acc))Recent advances
Synchronization
For comparatively large models, the uplink computation cost is high due to limited network connection speeds and a large number of clients. There are two possible solutions:
Structured updates: directly learn an update from a restricted space that can be parametrised using fewer variables.
Sketched updates: learn a full model update, then compress it before sending it to the server.
Single client performance
Due to the heterogeneity of medical data from various scanners and patient demographics, the performance of FL for the individual client is not satisfactory. Jiang et al. proposed an inside-outside personalisation approach to tackle this challenge. Each client learns a local adapted model as the inside personalised model by injecting both global and local gradients for inside clients. For outside clients, a diverse and informative routing space is constructed with the local, personalised models and the global models, from which an external personalised model is dynamically updated at test time.

Reference
[1] Xu, J., Glicksberg, B.S., Su, C., Walker, P., Bian, J. and Wang, F., 2021. Federated learning for healthcare informatics. Journal of Healthcare Informatics Research, 5(1), pp.1-19.
[2] Wiki, Federated learning
[3] Konečný, J., McMahan, H.B., Yu, F.X., Richtárik, P., Suresh, A.T. and Bacon, D., 2016. Federated learning: Strategies for improving communication efficiency. arXiv preprint arXiv:1610.05492.
[4] Jiang, M., Yang, H., Cheng, C. and Dou, Q., 2022. IOP-FL: Inside-Outside personalisation for Federated Medical Image Segmentation. arXiv preprint arXiv:2204.08467.
[5] Dayan, I., Roth, H.R., Zhong, A., Harouni, A., Gentili, A., Abidin, A.Z., Liu, A., Costa, A.B., Wood, B.J., Tsai, C.S. and Wang, C.H., 2021. Federated learning for predicting clinical outcomes in patients with COVID-19. Nature medicine, 27(10), pp.1735-1743.
[6] McMahan, B., Moore, E., Ramage, D., Hampson, S. and y Arcas, B.A., 2017, April. Communication-efficient learning of deep networks from decentralised data. In Artificial intelligence and statistics (pp. 1273-1282). PMLR.
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!