Good thoughts in 2023
Last updated on:2 years ago
There are good thoughts accumulated in 2023.
Good thought
Age learning
- Machine learning is based on the former human experience
- Only several types of data are not enough for a humanficial intelligence.
- Learning all materials that can be sensed (videos, language, light, wave, etc.)
Outdated
- Introduce data augmentation in rotjigsaw
M-CNN
Similar to Gaussian noise, random resize crop
- Literature review: MAE, others, check if anyone aleady done this
- Data augmentation design can reference MAE
- Slice and merge schemes
- recover to a larger featuremap is workable?
Pipline:
- Slice, select, sew, resize, encode, decode, similarity loss for ori and output
- Slice, select, sew, encode, decode, resize, similarity loss for ori and output
needs a considerable number of experiemnts, which we can’t afford now
- layer sleep Efficient Self-supervised Continual Learning with Progressive Task-correlated Layer Freezing
- channel sleep
- kernel sleep Rethinking 1×1 Convolutions: Can we train CNNs with Frozen Random Filters?
- instance segmentation on COCO
- Design a new decoder for mixupmask (a question: what kinds of decoder can be transferred?)
- Step weight freezing in transfer learning (difficult to ensure how many layers needed to be frozen, most of the datasets I used fall in “small” scale region)
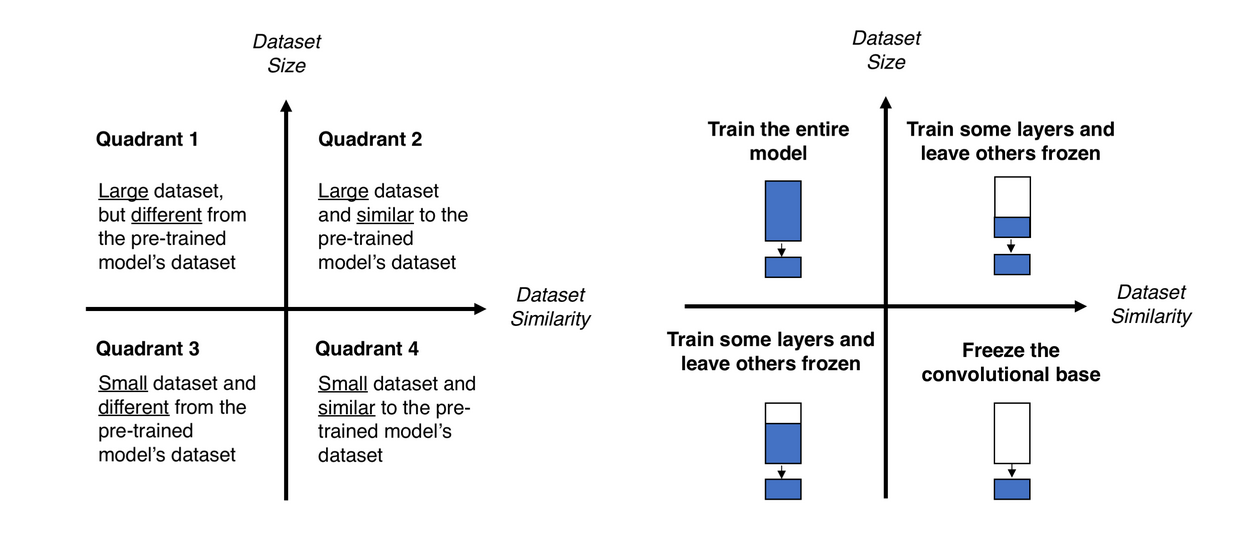
Finished
- Do BYOL, SAWV, BARLOW and cocor experiments for FullRot. Submit the paper to PR
- U-Net for MixupMask
- Directly segmentation pretext, fully unsupervised segmentation crop region with random ratio and angle
- Can set loss monitor to accumulate different loss by scale, not working, maybe adaptive loss, check multi-loss works
- Model does not know which rotated image is the background
Reference
What is the right way to gradually unfreeze layers in neural network while learning with tensorflow?
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!