Inception network - Class Review
Last updated on:3 years ago
Instead of you needing to pick one of these filter sizes or pooling you want and committing to that, you can do them all and just concatenate all the outputs.
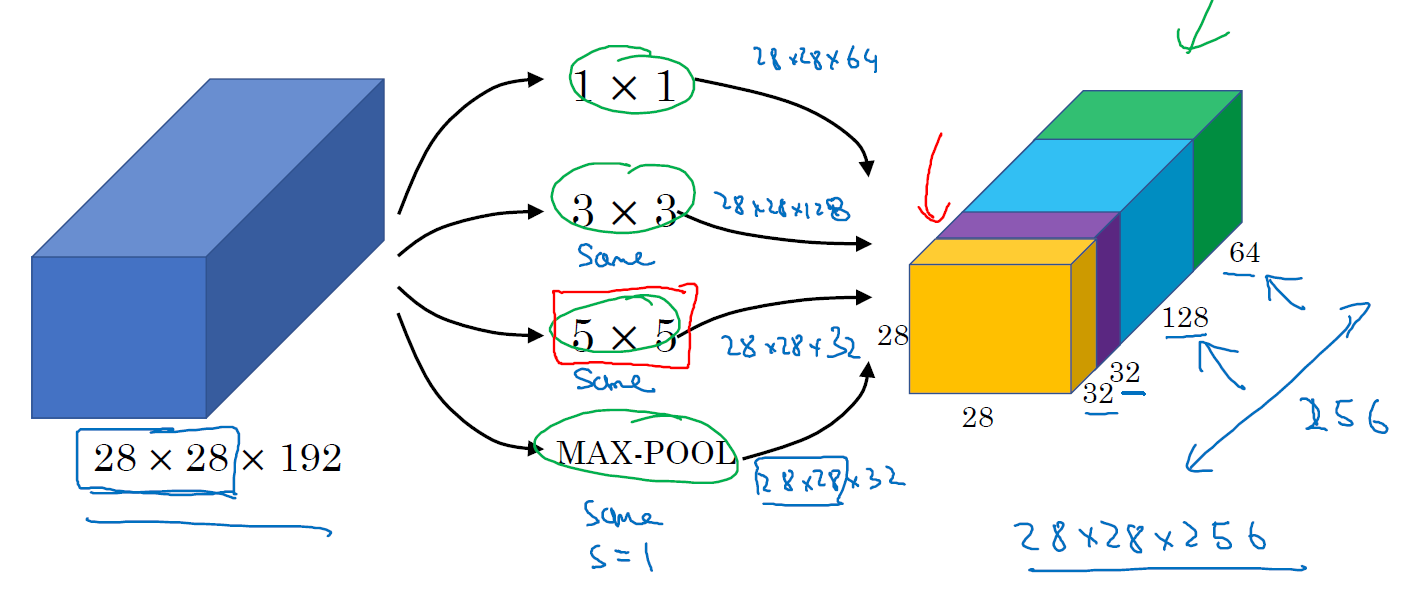
Inception network
Since pooling operations have been essential for the success of current convolutional networks, it suggests that adding an alternative parallel pooling path in each such stage should have additional benefit, too.
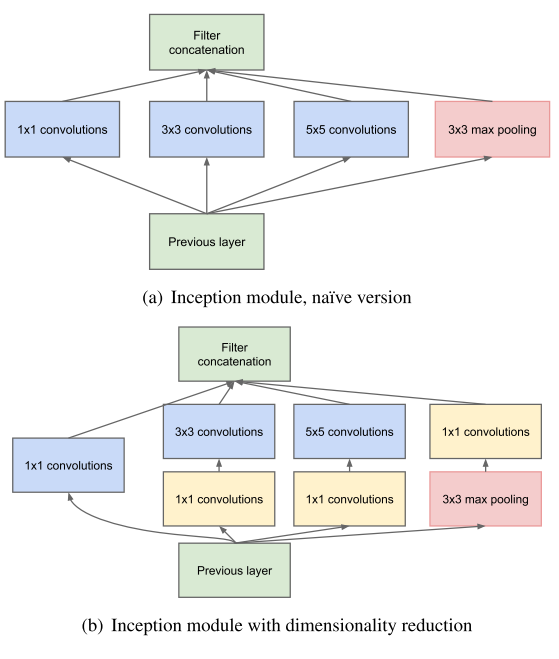
Their output correlation statistics are bound to vary. The ratio of 3×3 and 5×5 convolutions should increase as we move to higher layers.
The problem of computational cost
Even a modest number of 5×5 convolutions can be prohibitively expensive on top of a convolutional layer with a large number of filter.
Solutions: judiciously reducing dimension wherever the computational requirements would increase too much otherwise, which is based on the success of embeddings.
Q&A
7.Which ones of the following statements on Inception Networks are true? (Check all that apply.)
-[x] A single inception block allows the network to use a combination of 1x1, 3x3, 5x5 convolutions and pooling.
-[ ] Inception networks incorporate a variety of network architectures (similar to dropout, which randomly chooses a network architecture on each step) and thus has a similar regularizing effect as dropout.
-[ ] Making an inception network deeper (by stacking more inception blocks together) might not hurt training set performance.
-[x] Inception blocks usually use 1x1 convolutions to reduce the input data volume’s size before applying 3x3 and 5x5 convolutions.
Reference
[1] Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V. and Rabinovich, A., 2015. Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1-9).
[2] Deeplearning.ai, Convolutional Neural Networks
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!