Semantic segmentation with U-Net - Class review
Last updated on:7 months ago
Semantic image segmentation predicts a label for every single pixel in an image with appropriate class labels.
Semantic segmentation with U-Net
Semantic segmentation: Locating objects in an image by predicting each pixel as to which class it belongs to.
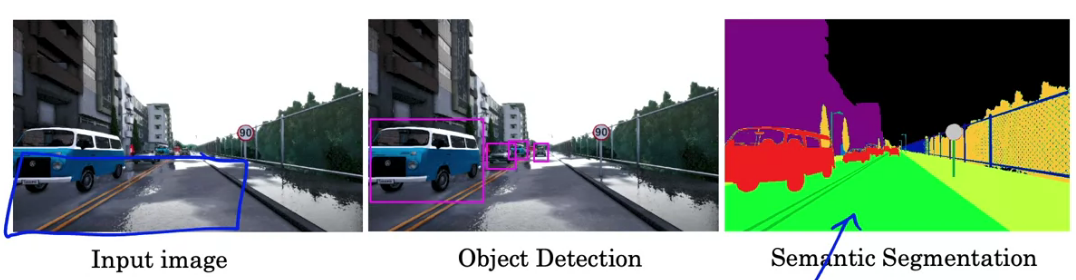
Motivation for U-Net
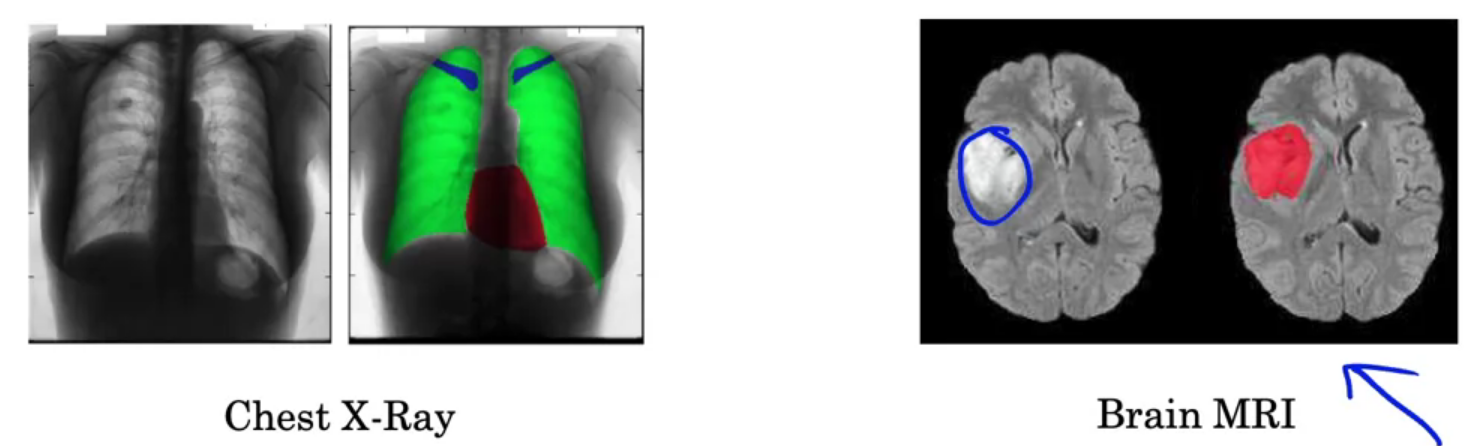
per-pixel class labels
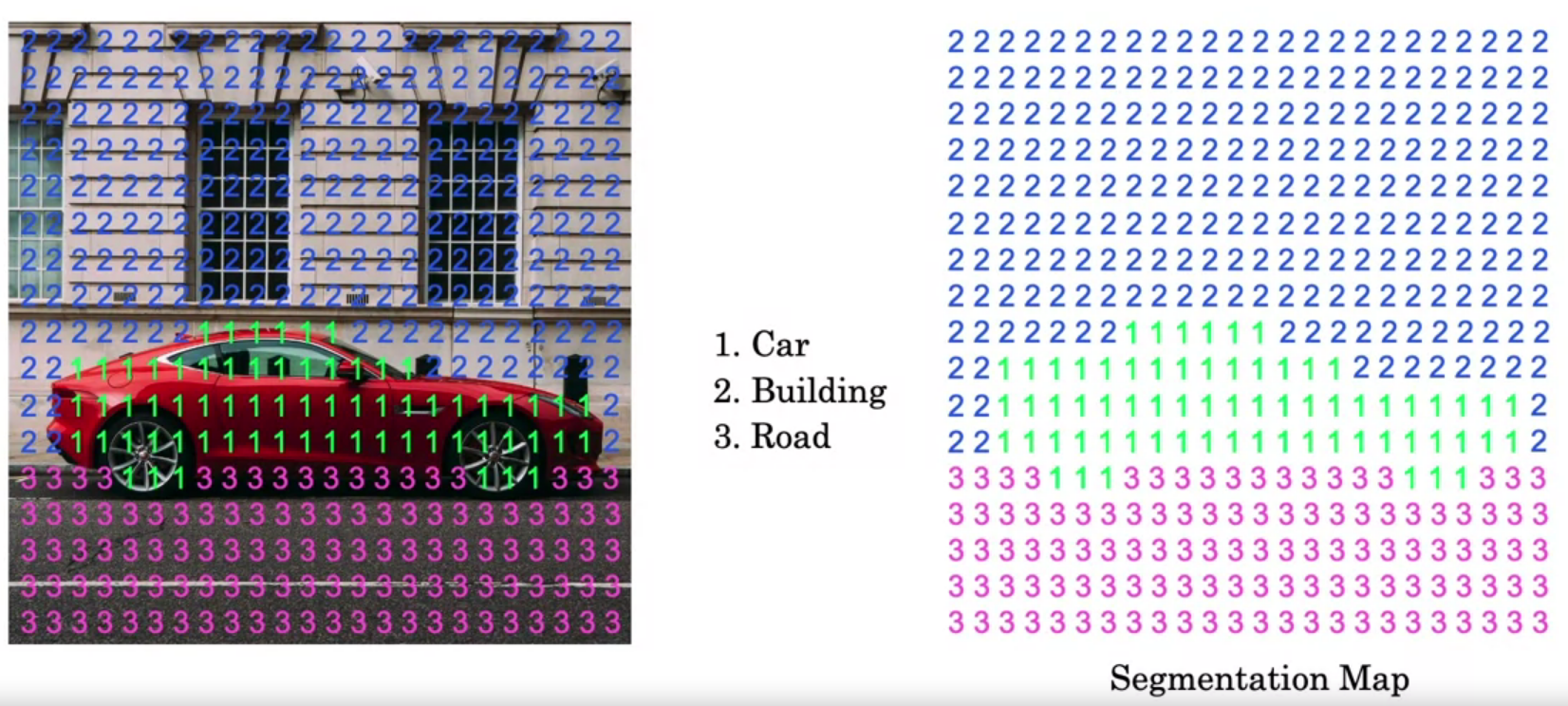
Output: segmentation map
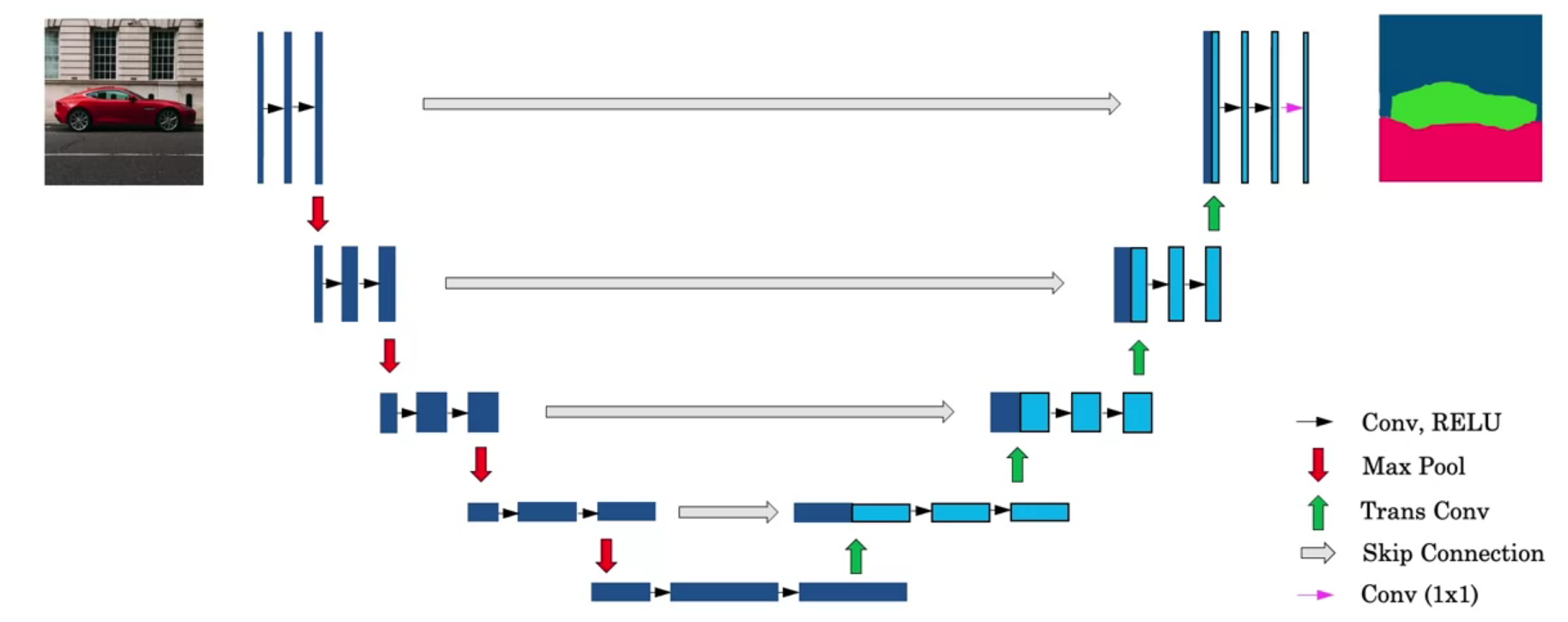
U-Net uses an equal number of convolutional blocks and transposed convolutions for down-sampling and up-sampling.
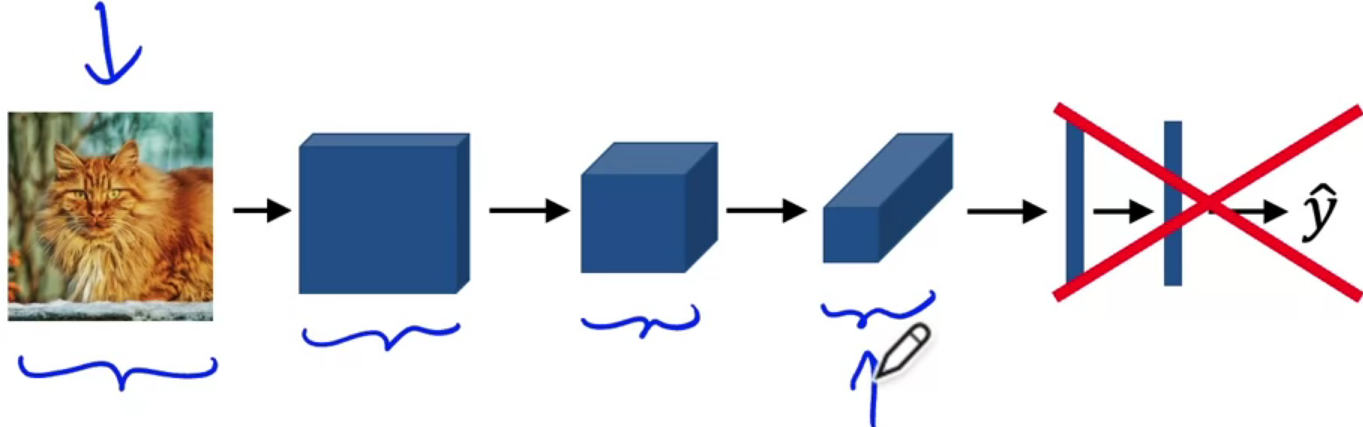
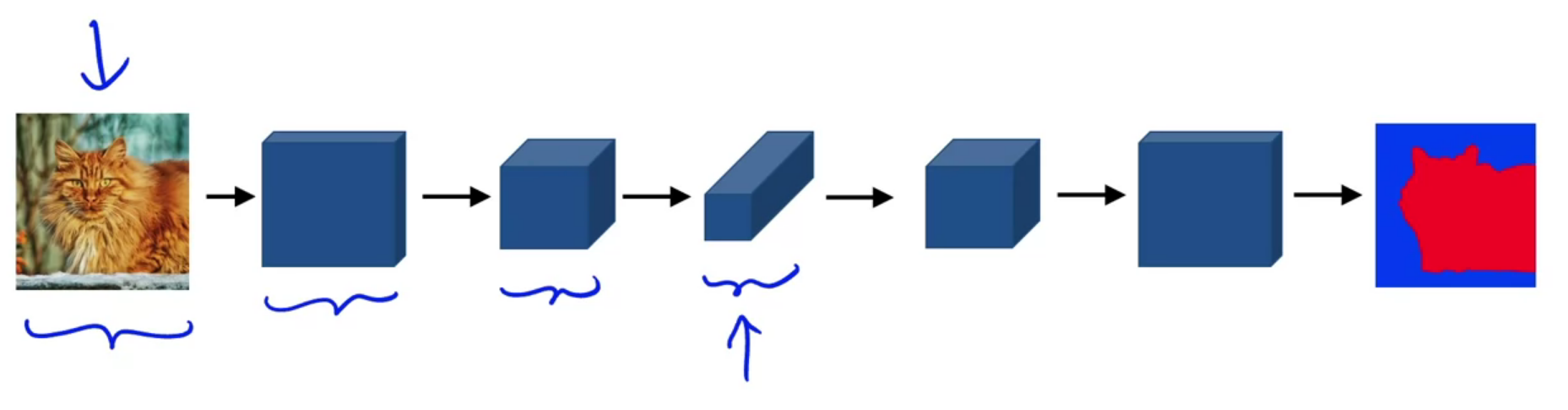
Deep learning for semantic segmentation
Output: $h \times w \times n$, where n = number of output classes
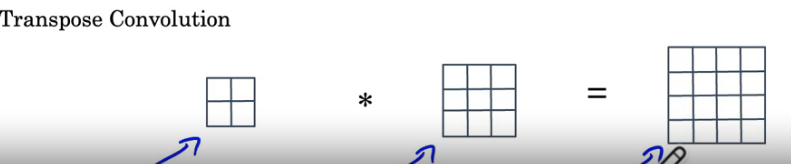
Transpose convolution
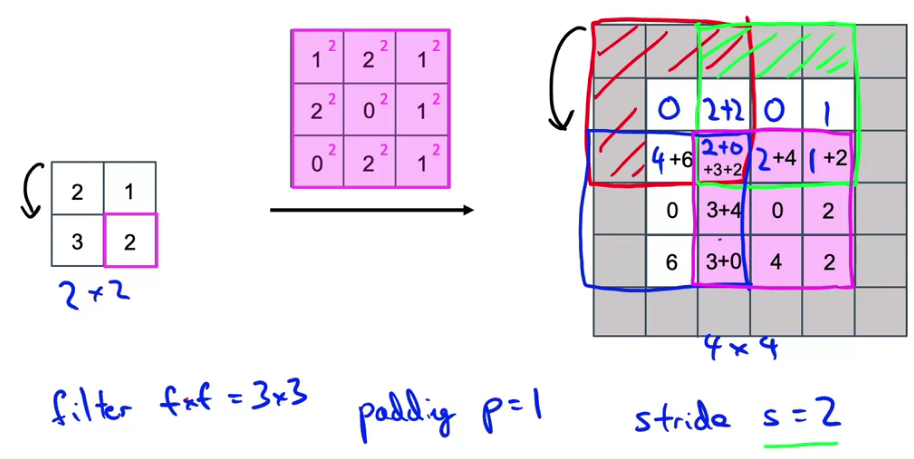
Output dimension: $s(n_h - 1) + f_h - 2p \times s(n_w - 1) + f_w - 2p$, where n is input size without channel size, f is kernel size, and then p is padding, s is stride.
Motivation: turn a small input into a bigger output. Ignore padding region, add overlap values together
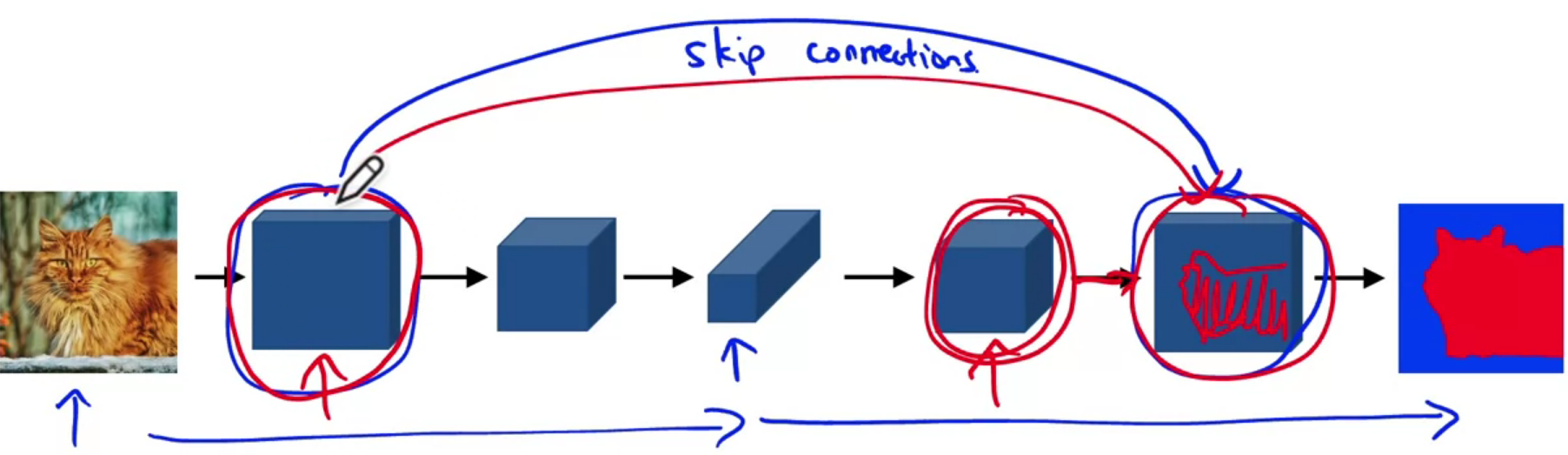
U-Net Architecture
Skip connections are used to prevent border pixel information loss and overfitting in U-Net. Draw it which looks like a U.
align_corners in segmentation
Here is a simple illustration I made showing how a $4\times4$ image is upsampled to $8\times8$.
When aligh_corners=True, pixels are regarded as a grid of points.
Points at the corners are aligned.
When aligh_corners=False, pixels are regarded as $1\times1$ areas.
Area boundaries, rather than their centers, are aligned.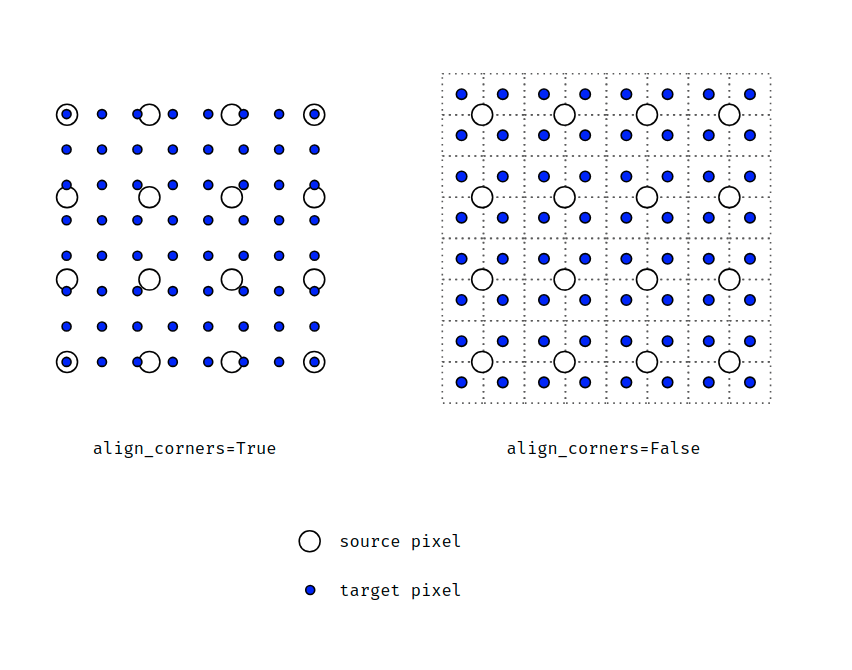
I had issue with my Unet not being equivariant to translations. Turns out align_corners=True was the culprit. As your figure clearly shows in the “True” case there is a shift between the input and output grids that depends on location. This add spatial bias in Unets. Your pic helped see this fast.
False is better in PASCAL VOC segmentation. (Deeplab, rescon, reslink)
Reference
[1] Deeplearning.ai, Convolutional Neural Networks
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!