Generative AI and its building blocks
Last updated on:3 months ago
Generative artificial intelligence booms again at the rise of large language models, which usually play an essential role in generative content in chatbots.
Generative artificial intelligence
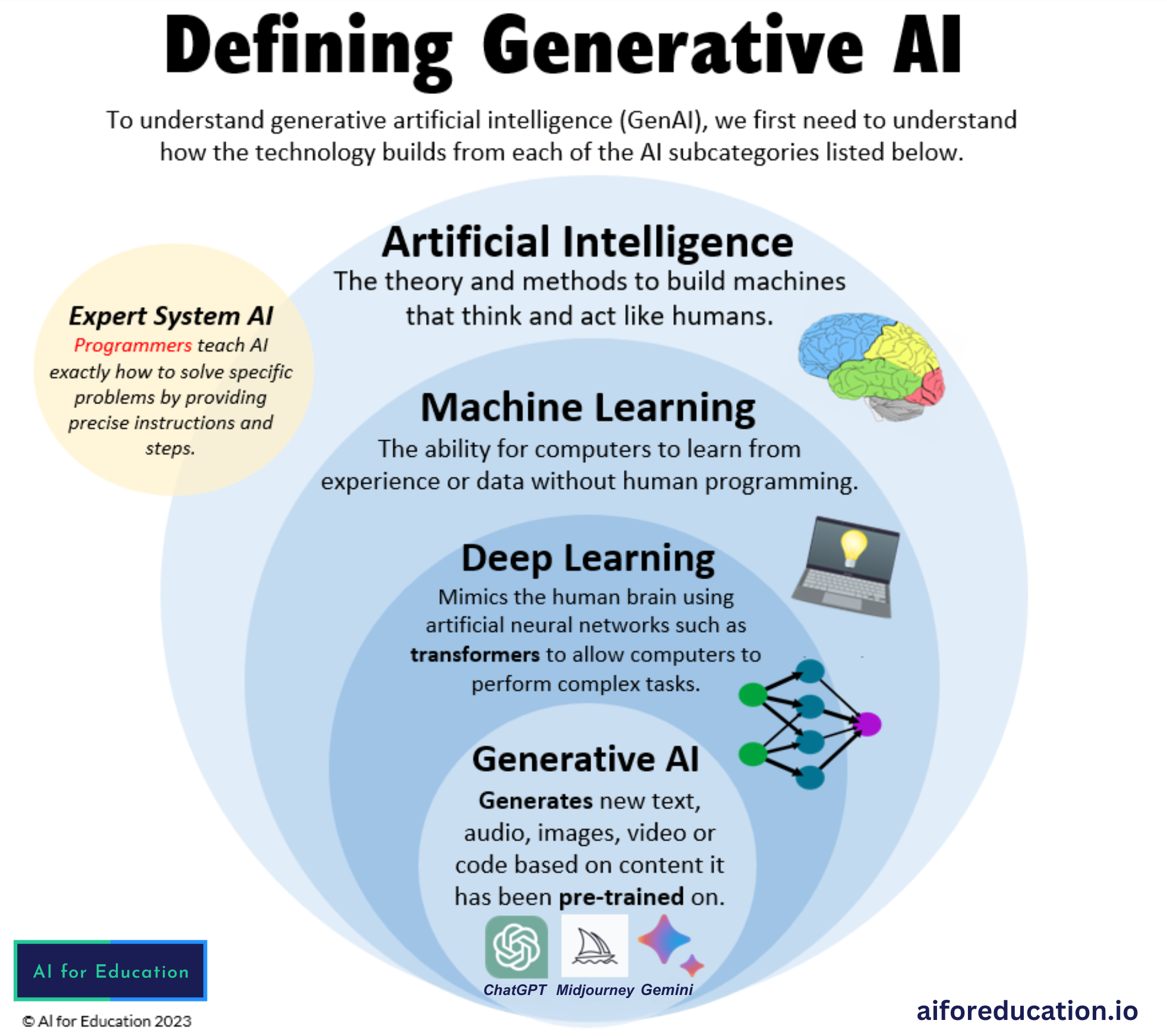
Introduction to generative AI
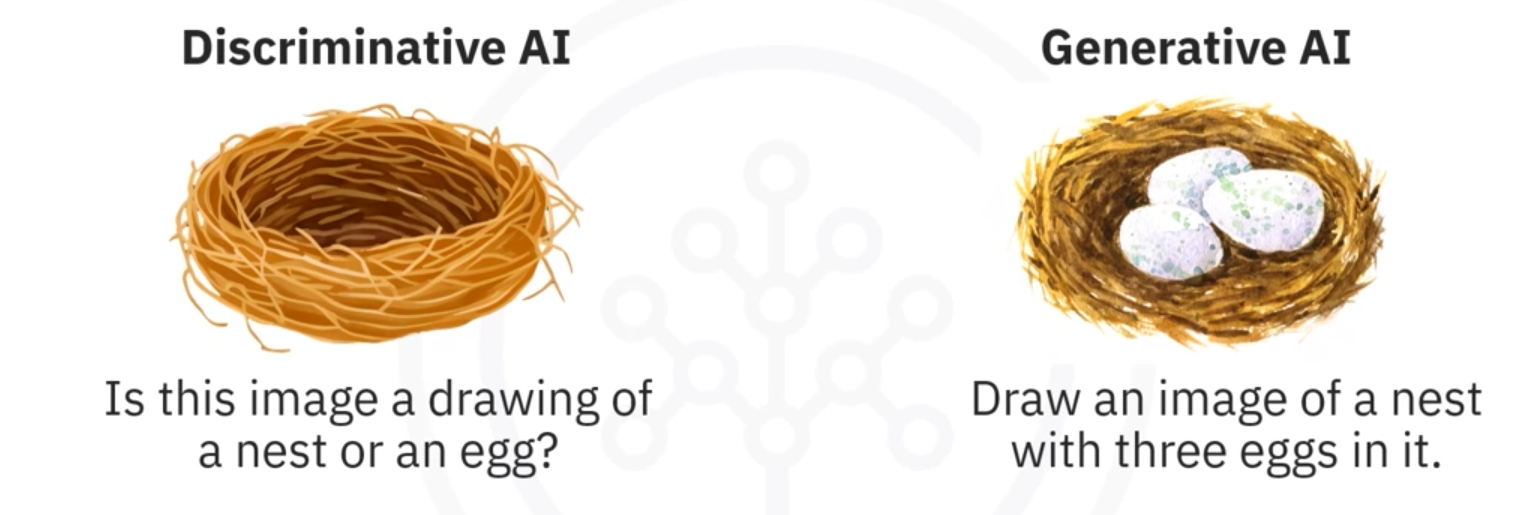
There are two main AI categories: Discriminative AI vs. Generative AI.
Generative AI is a subfield of artificial intelligence that uses generative models to produce text, images, videos, or other forms of data (produce/create data). These models learn the underlying patterns and structures of their training data and use them to produce new data.
Discriminative AI, or traditional AI, focuses on classifying or predicting outcomes based on existing data. It leans patterns to distinguish between different categories or classes rather than generating new data or content.
Input and output data forms
Input: prompt -> Text, Image, video, and other input forms.
Output: Text, Image, audio, code, video, and other forms of data.
Remember: prompt and output are different concepts.
Building blocks for generative AI
Types:
- Generative adversarial networks (GANs): generate data and discriminate it from true data.
- Variational autoencoders (VAEs): compress and reconstruct data.
- Transformers: capture long-range sequence, global information, and strong ability to understand complex scenes.
- Diffusion models: denoise.
Generative adversarial networks (GANs)
A framework estimates generative models via an adversarial process, in which two models are simultaneously trained: a generative model $G$ that captures the data distribution, and a discriminative model $D$ that estimates the probability that a sample came from the training data rather than $G$. The training procedure for $G$ is to maximise the probability of $D$ making a mistake.
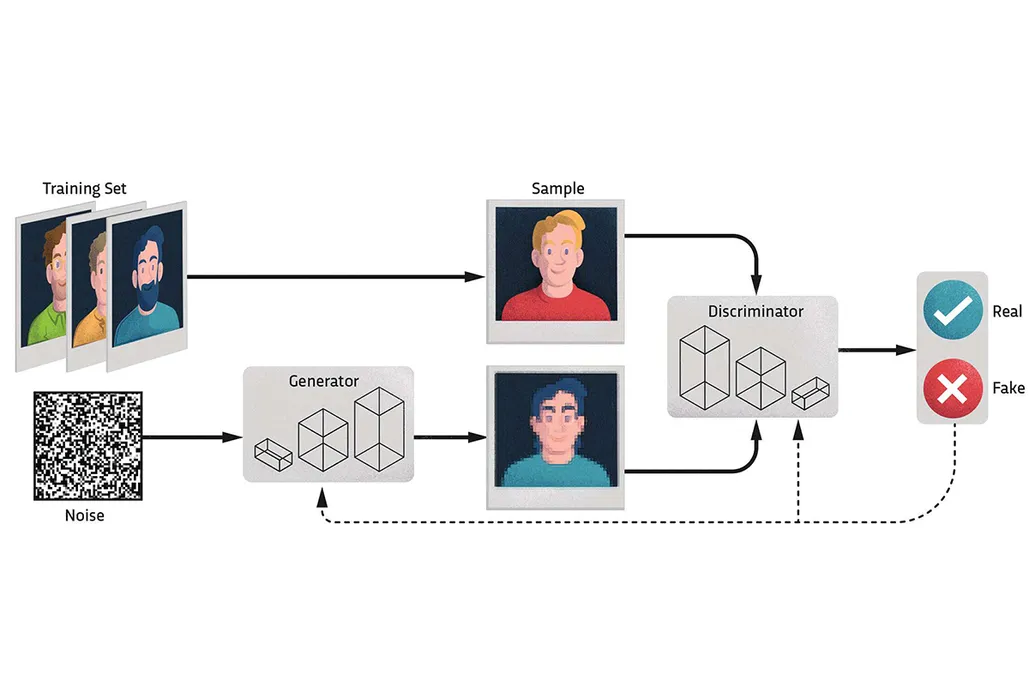
On the one hand, $D$ is trained to maximise the probability ($\log D(\mathbf{x})$) by assigning the correct label to both training examples and samples from $G$. On the other hand, $G$ is trained to minimise $\log (1 - D(G(\mathbf{z})))$.
$$
\min_G \max_D V(D, G) = \mathbb{E}_{\mathbf{x} \sim p_{\text{data}}(\mathbf{x})}[\log D(\mathbf{x})] + \mathbb{E}_{\mathbf{z} \sim p_{\mathbf{z}}(\mathbf{z})}[\log (1 - D(G(\mathbf{z})))]
$$
The equation may not provide sufficient gradient for $G$ to learn well. Early in learning, when $G$ is poor, $D$ can reject samples with high confidence because they differ from the training data. In this case, $\log (1 - D(G(\mathbf{z})))$ fails. Instead, we can train $G$ to maximise $\log D(G(\mathbf{z}))$. Only when both $G$ and $D$ have enough capability is the original equation is appropriate.
Therefore, the essential elements of GANs include the design of loss functions, which should not only enhance the generator’s ($G$) ability to accurately capture data distributions and patterns but also ensure that the discriminator ($D$) can effectively distinguish between real and generated fake data.
Please see Introduction of generative adversarial networks (GANs) for details.
Codes
adversarial_loss = torch.nn.MSELoss()
categorical_loss = torch.nn.CrossEntropyLoss()
continuous_loss = torch.nn.MSELoss()
""" Train Generator """
# Loss measures the generator's ability to fool the discriminator
validity, _, _ = discriminator(gen_imgs)
g_loss = adversarial_loss(validity, valid)
""" Train Discriminator """
# Loss for real images
real_pred, _, _ = discriminator(real_imgs)
d_real_loss = adversarial_loss(real_pred, valid)
# Loss for fake images
fake_pred, _, _ = discriminator(gen_imgs.detach())
d_fake_loss = adversarial_loss(fake_pred, fake)'
# Total discriminator loss
d_loss = (d_real_loss + d_fake_loss) / 2
""" Information Loss """
# Sample labels
sampled_labels = np.random.randint(0, opt.n_classes, batch_size)
# Ground truth labels
gt_labels = Variable(LongTensor(sampled_labels), requires_grad=False)
# Sample noise, labels and code as generator input
z = Variable(FloatTensor(np.random.normal(0, 1, (batch_size, opt.latent_dim))))
label_input = to_categorical(sampled_labels, num_columns=opt.n_classes)
code_input = Variable(FloatTensor(np.random.uniform(-1, 1, (batch_size, opt.code_dim))))
gen_imgs = generator(z, label_input, code_input)
_, pred_label, pred_code = discriminator(gen_imgs)
info_loss = lambda_cat * categorical_loss(pred_label, gt_labels) + lambda_con * continuous_loss(
pred_code, code_input
)Variational autoencoders (VAEs)
An autoencoder is a specific type of neural network, which is mainly designed to encode the input into a compressed and meaningful representation, and then decode it back/reconstruct such that the reconstructed input is similar as possible to the original one.
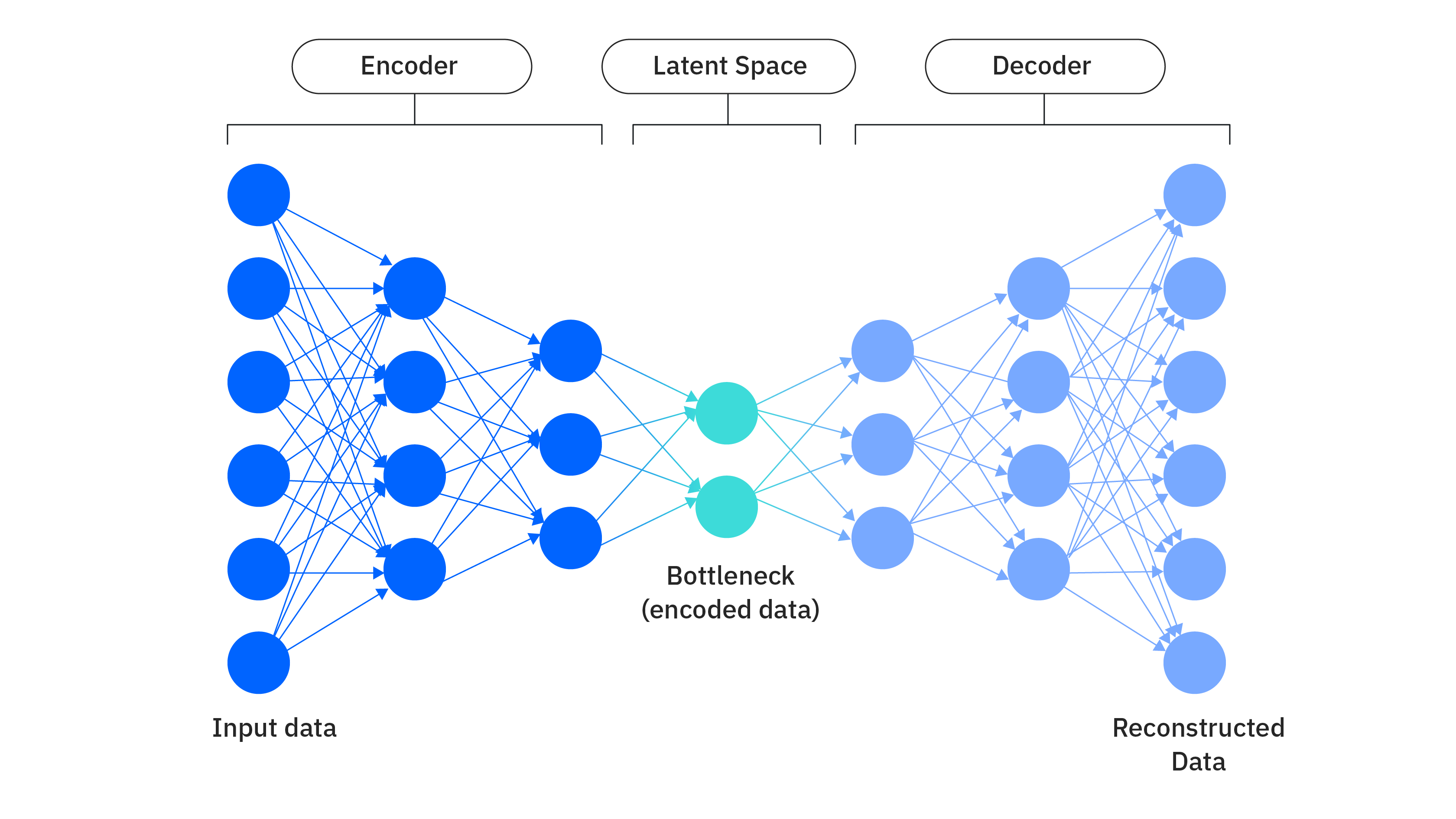
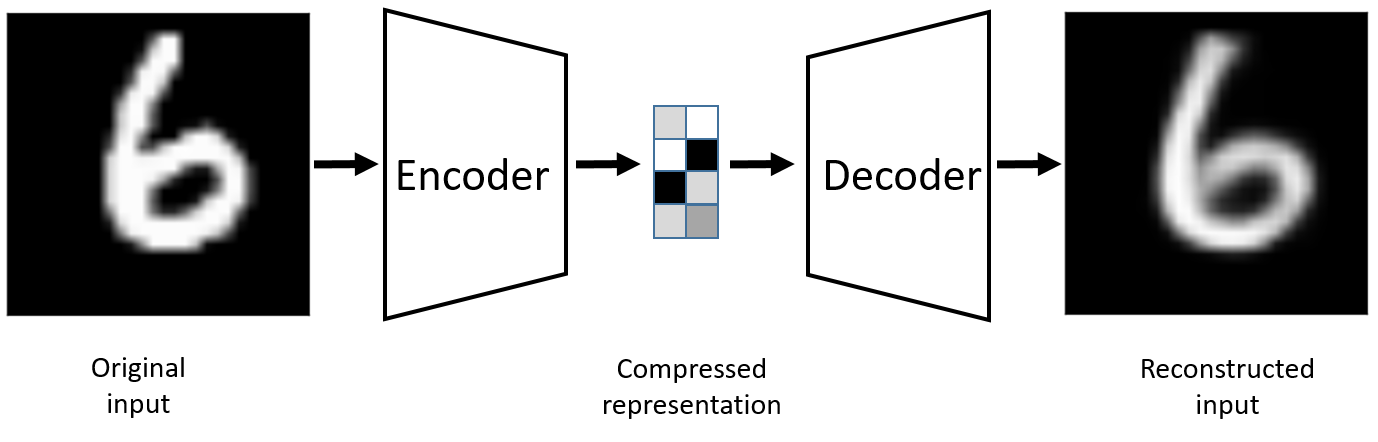
Mask autoencoder
Masked autoencoder (MAE) is a subset of autoencoder, which applies the masked patches tricks to compress the information and reconstruct the image through a decoder. In the official statement, He et al. said, “we masked random patches of the input image and reconstruct the missing pixels“.
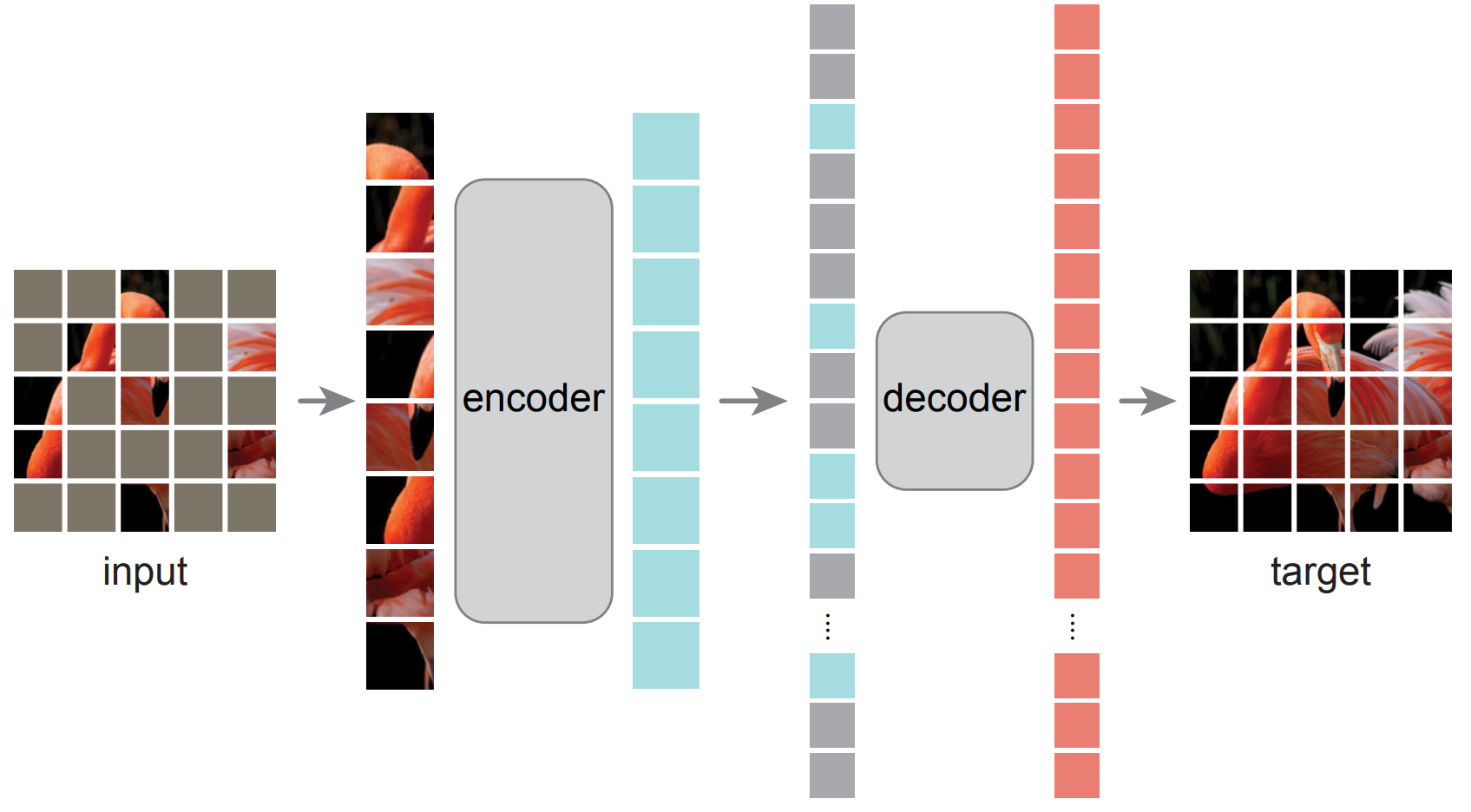
The loss function of MAE computes the mean squared error (MSE) between the reconstructed and original images in the pixel space.
Codes
Masked autoencoder’s MSE loss:
def forward_loss(self, image, pred, mask):
"""
imgs: [N, 3, H, W]
pred: [N, L, p*p*3]
mask: [N, L], 0 is keep, 1 is remove,
"""
target = self.patchify(imgs)
if self.norm_pix_loss:
# applied if used mean-std normalisation
mean = target.mean(dim=-1, keepdim=True)
var = target.var(dim=-1, keepdim=True)
target = (target - mean) / (var + 1.e-6)**.5
loss = (pred - target) ** 2
loss = loss.mean(dim=-1) # [N, L], mean loss per patch
loss = (loss * mask).sum() / mask.sum() # mean loss on removed patches
return lossTransformers
Transformers are a type of neural network architecture used in deep learning, particularly for processing and generating sequential data like text and images. They excel at capturing long-range dependencies and contextual relationships within sequences, making them highly effective for tasks like machine translation, text summarisation, and language models.
For details, please see Vision transformer: A new way to analyse image.
Main component: multi-head self-attention + MLP.
ViTs vs. CNNs on vision foundation models
Foundation models increasing utilise vision transformers (ViTs) as their backbone due to the ViT’s ability to capture global relationships within images, which is crucial for understanding complex scenes and performing various vision tasks. Compared to CNNs, which primarily focus on local features, ViTs can model the entire image simultaneously, leading to more robust and accurate feature extraction.
Codes
SAM multi-head self-attention:
class Attention(nn.Module):
"""Multi-head Attention block with relative position embeddings."""
def __init__(
self,
dim: int,
num_heads: int = 8,
qkv_bias: bool = True,
use_rel_pos: bool = False,
rel_pos_zero_init: bool = True,
input_size: Optional[Tuple[int, int]] = None,
) -> None:
"""
Args:
dim (int): Number of input channels.
num_heads (int): Number of attention heads.
qkv_bias (bool): If True, add a learnable bias to query, key, value.
rel_pos (bool): If True, add relative positional embeddings to the attention map.
rel_pos_zero_init (bool): If True, zero initialises relative positional parameters.
input_size (tuple(int, int) or None): Input resolution for calculating the relative
positional parameter size.
"""
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim**-0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.proj = nn.Linear(dim, dim)
self.use_rel_pos = use_rel_pos
if self.use_rel_pos:
assert (
input_size is not None
), "Input size must be provided if using relative positional encoding."
# initialise relative positional embeddings
self.rel_pos_h = nn.Parameter(torch.zeros(2 * input_size[0] - 1, head_dim))
self.rel_pos_w = nn.Parameter(torch.zeros(2 * input_size[1] - 1, head_dim))
def forward(self, x: torch.Tensor) -> torch.Tensor:
B, H, W, _ = x.shape
# qkv with shape (3, B, nHead, H * W, C)
qkv = self.qkv(x).reshape(B, H * W, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4)
# q, k, v with shape (B * nHead, H * W, C)
q, k, v = qkv.reshape(3, B * self.num_heads, H * W, -1).unbind(0)
attn = (q * self.scale) @ k.transpose(-2, -1)
if self.use_rel_pos:
attn = add_decomposed_rel_pos(attn, q, self.rel_pos_h, self.rel_pos_w, (H, W), (H, W))
attn = attn.softmax(dim=-1)
x = (attn @ v).view(B, self.num_heads, H, W, -1).permute(0, 2, 3, 1, 4).reshape(B, H, W, -1)
x = self.proj(x)
return xDiffusion models
Diffusion models are a type of generative model that learn to generate data by progressively adding noise to it and then learning to reverse this process. They are particularly effective at generating high-quality, realistic images and other data types.

Codes
Diffusion loss, add noise:
def p_losses(self, denoise_fn, x_start, t, noise=None):
"""
Training loss calculation
"""
B, H, W, C = x_start.shape.as_list()
assert t.shape == [B]
if noise is None:
noise = tf.random_normal(shape=x_start.shape, dtype=x_start.dtype)
assert noise.shape == x_start.shape and noise.dtype == x_start.dtype
x_noisy = self.q_sample(x_start=x_start, t=t, noise=noise)
x_recon = denoise_fn(x_noisy, t)
assert x_noisy.shape == x_start.shape
assert x_recon.shape[:3] == [B, H, W] and len(x_recon.shape) == 4
if self.loss_type == 'noisepred':
# predict the noise instead of x_start. seems to be weighted naturally like SNR
assert x_recon.shape == x_start.shape
losses = nn.meanflat(tf.squared_difference(noise, x_recon))
else:
raise NotImplementedError(self.loss_type)
assert losses.shape == [B]
return lossesDenoise function, predict the noise instead of x_start.
def _denoise(self, x, t, y, dropout):
B, H, W, C = x.shape.as_list()
assert x.dtype == tf.float32
assert t.shape == [B] and t.dtype in [tf.int32, tf.int64]
assert y.shape == [B] and y.dtype in [tf.int32, tf.int64]
orig_out_ch = out_ch = C
if self.block_size != 1:
x = tf.nn.space_to_depth(x, self.block_size)
out_ch *= self.block_size ** 2
y = None
if self.model_name == 'unet2d16b2c112244': # 114M for block_size=1
out = unet.model(
x, t=t, y=y, name='model', ch=128, ch_mult=(1, 1, 2, 2, 4, 4), num_res_blocks=2, attn_resolutions=(16,),
out_ch=out_ch, num_classes=self.num_classes, dropout=dropout
)
else:
raise NotImplementedError(self.model_name)
if self.block_size != 1:
out = tf.nn.depth_to_space(out, self.block_size)
assert out.shape == [B, H, W, orig_out_ch]
return outDispersive loss
The original InfoNCE loss can be interpreted as a categorical cross-entropy objective that encourages high similarity between positive pairs and low similarity between negative pairs:
$$
\mathcal{L}_{\text{Contrast}}
= - \log \frac{\exp \bigl(-\mathcal{D} \bigl(z_i, z_i^+\bigr)/\tau\bigr)}{\sum_j \exp \bigl(-\mathcal{D} \bigl(z_i, z_j\bigr)/\tau\bigr)}.
$$
Here, $(z_i, z_i^+)$ denotes a pair of positive samples (e.g.,, obtained by data augmentation of the same image), and $(z_i, z_j)$ denotes any pair of samples which include the positive pair and all negative pairs (i.e., $i \neq j$). $\mathcal{D}$ denotes a dissimilarity function (e.g., distance), and $\tau$ is a hyper-parameter known as the temperature. A commonly used form of $\mathcal{D}$ is the negative cosine similarity: $(\mathcal{D}(z_i,z_j) = -{z_i^\top z_j}/{(|z_i||z_j|)})$.
Inside the logarithm, the numerator involves only the positive pair $((z_i, z_i^+))$, whereas the denominator includes all pairs in the batch.
We can rewrite equivalently as:
$$
\mathcal{L}_{\text{Contrast}} = \mathcal{D} \left(z_i, z_i^+\right)/\tau + \log \sum_j \exp \bigl(-\mathcal{D} \bigl(z_i, z_j\bigr)/\tau\bigr).
$$
Here, the first term is similar to a regression objective, which minimizes the distance between $z_i$ and its target $z_i^+$.
On the other hand, the second term encourages any pair of $(z_i, z_j)$ to be as distant as possible.
To construct the Dispersive Loss counterpart, we keep only the second term:
$$
\mathcal{L}_{\text{Disp}} = \log \sum_j \exp \bigl(-\mathcal{D} \bigl(z_i, z_j\bigr)/\tau\bigr).
$$
This formulation can also be viewed as a contrastive loss, where each positive pair consists of two identical views $z_i^+=z_i$, making $\mathcal{D} \left(z_i, z_i^+\right)$ a constant.
$$
\mathcal{L}_{\text{Disp}}
= \log \mathbb{E}_{i,j} \bigl[\exp \bigl(-\mathcal{D} \bigl(z_i, z_j\bigr)/\tau\bigr)\bigr].
$$
This loss function has the same value for all samples within a batch and is computed only once per batch. In our experiments, in addition to the cosine dissimilarity, we also study the squared $(\ell_2)$ distance: $(\mathcal{D} \bigl(z_i, z_j\bigr) = |z_i - z_j|_2^2)$. When using this $(\ell_2)$ form, the Dispersive Loss can be easily computed by a few lines of code.
Codes
def disp_loss(Z, tau):
# Euclidean distance
D = pdist(Z, p=2)**2
return log(mean(exp(-D/tau)))
def loss(pred, Z, tgt, lamb):
L_diff = mean((pred - tgt)**2)
L_disp = disp_loss(Z)
return L_diff + lamb * L_dispReference
- Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A. and Bengio, Y., 2020. Generative adversarial networks. Communications of the ACM, 63(11), pp.139-144.
- adversarial
- PyTorch-GAN
- Introduction of generative adversarial networks (GANs)
- Generative artificial intelligence
- Generative AI for Everyone
- Generative AI: Foundation Models and Platforms
- Michelucci, U., 2022. An introduction to autoencoders. arXiv preprint arXiv:2201.03898.
- He, K., Chen, X., Xie, S., Li, Y., Dollár, P. and Girshick, R., 2022. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 16000-16009).
- mae
- Vision transformer: A new way to analyse image
- segment-anything
- Ho, J., Jain, A. and Abbeel, P., 2020. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33, pp.6840-6851.
- diffusion
- Wang, R. and He, K., 2025. Diffuse and Disperse: Image Generation with Representation Regularization. arXiv preprint arXiv:2506.09027.
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!