What is a large language model, and how does it work?
Last updated on:12 days ago
Large language models (LLMs) are a subset of foundation models that can perform various natural language processing (NLP) tasks. LLMs are a more powerful and sophisticated version of a standard language model.
Introduction
What is a large language model?
With the rise of LLMs, generative AI tools have become more common since an “AI boom” in the 2020s. This boom was made possible by improvements in transformer-based deep neural networks and large language models.
A large language model (LLM) is a language model trained with self-supervised machine learning on a vast amount of text, designed for natural language processing tasks, especially language generation.
The largest and most capable LLMs are generative pretrained transformers (GPTs), mainly used in generative chatbots such as ChatGPT or Gemini. LLMs can be fine-tuned for specific tasks or guided by prompt engineering.
Relatives to language models
A language model is a statistical model that predicts the next word or words in a sequence of text. In contrast, a large language model is a specific type of language model with significantly more parameters and training data. An LLM is a more powerful and sophisticated version of a standard language model.
Relatives to foundation models
All LLMs are foundation models, but not all foundation models are LLMs.
Foundation generative AI models are distinct from other generative AI models because they exhibit broad capabilities that can be adapted to a range of different and specific tasks.
Generative AI
Generative artificial intelligence is a method that applies generative models to produce text, images, videos, and other data. Generative AI learns underlying patterns and structures from its training dataset and produces new data.
Please see Introduction of generative adversarial networks (GANs) and Generative AI and its building blocks for details.
Advantages
Aid in learning, enable efficiency, enhance creativity, enable engaging and interactive conversations, Increase productivity, enable communication, and content localization.
Application/how does it work?
There are three basic applications:
- Interpret context, grammar, and semantics.
- Draw statistical relationships between words and phrases.
- Adapt creative styles based on the given context.
Basic blocks
Recurrent neural network
A recurrent neural network (RNN) is a type of neural network designed to process sequential data, like text, speech/audio, or time series. Unlike standard feedforward neural networks, RNNs have a feedback loop that allows them to “remember” information from previous inputs, enabling them to understand context and dependencies within sequences.
The RNN is the repeated use of a single cell. A basic RNN reads inputs one at a timeand remembers information through the hidden layer activations (hidden states) that are passed from one step to the next.
Shortcommings: It only uses the information earlier in the sequence to make a prediction. Bidirectional RNN can solve this problem. But BRNN needs the entire sequence of data.
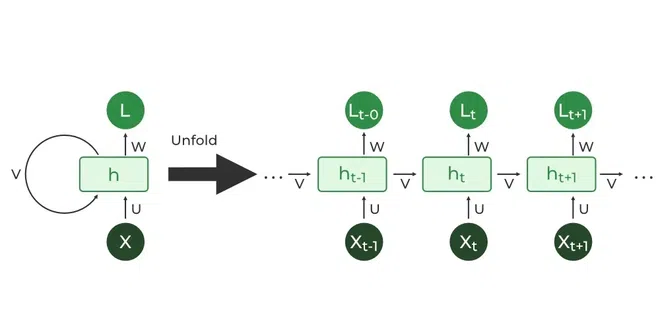
Please see Recurrent neural network (RNN) - Class Review for details.
Codes
Apply a multi-layer Elman RNN with tanh or ReLU non-linearity to an input sequence. For each element in the input sequence, each layer computes the following function:
$$h_t = \tanh(x_t W_{ih}^T + b_{ih} + h_{t-1}W_{hh}^T + b_{hh})$$
where $h_t$ is the hidden state at time $t$, $x_t$ is the input at time $t$ and $h(t-1)$ is the hidden state of the previous layer at time $t-1$ or initial hidden state at time $o$.
# Efficient implementation equivalent to the following with bidirectional=False
def forward(x, hx=None):
if batch_first:
x = x.transpose(0, 1)
seq_len, batch_size, _ = x.size()
if hx is None:
hx = torch.zeros(num_layers, batch_size, hidden_size)
h_t_minus_1 = hx
h_t = hx
output = []
for t in range(seq_len):
for layer in range(num_layers):
h_t[layer] = torch.tanh(
x[t] @ weight_ih[layer].T
+ bias_ih[layer]
+ h_t_minus_1[layer] @ weight_hh[layer].T
+ bias_hh[layer]
)
output.append(h_t[-1])
h_t_minus_1 = h_t
output = torch.stack(output)
if batch_first:
output = output.transpose(0, 1)
return output, h_tLong short-term memory
Long short-term memory (LSTM) is constructed by gate recurrent unit (GRU). LSTM is a type of RNN specifically designed to handle long-term dependencies in sequential data, overcoming a common problem with traditional RNNs called the vanishing gradient problem. Like vanilla RNN, LSTM excels at processing sequential data, like text, speech/audio, or time series. It is used in various applications such as language translation, speech recognition, and video analysis.
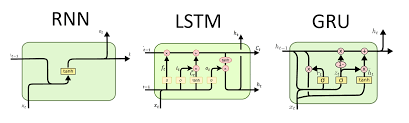
LSTM has three gates: forget gate, update gate, and output gate, which control the flow of information within its hidden unit.
Compared to the vanilla RNNs, LSTMs use gates to control the information flow, allowing them to retain relevant information for more extended periods.
Please see Recurrent neural network (RNN) - Class Review for details.
How each gate works
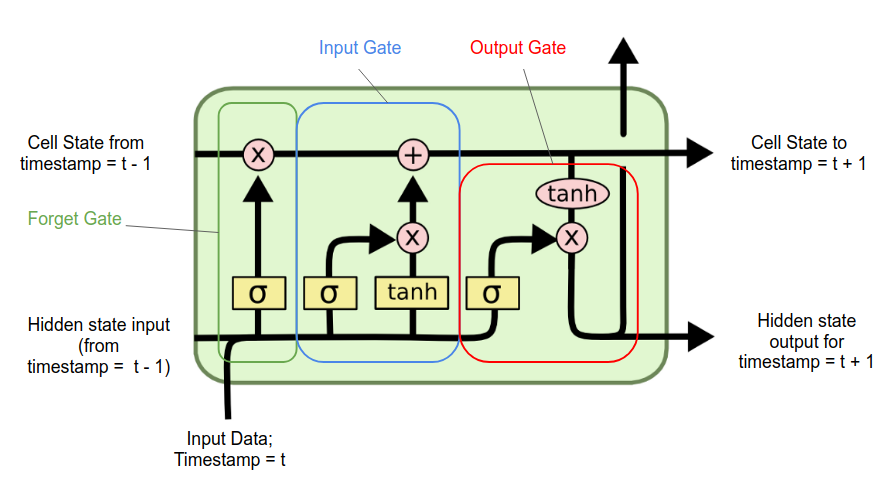
Forget gate:
Decide what information to discard from the previous cell state.
A sigmoid function for the previous hidden state is applied to get a vector ranging between 0 (forget) to 1 (keep). This vector is then multiplied element-wise with the previous cell state, effectively filtering out the irrelevant information.
Input gate:
Decide what new information from the current input is relevant and should be stored in the cell state.
A sigmoid layer determines which values to update. A tanh layer creates a vector of new candidates values that could be added to the cell state.
Output gate:
Decide which part of the current cell state to output as the hidden state for the next time step.
A sigmoid layer decides which parts of the cell state to output. The cell state is passed through a tanh activation function to scale its values between -1 and 1.
Codes
Apply a multi-layer long short-term memory (LSTM) RNN to an input sequence.
For each element in the input sequence, each layer computes the following
function:
$$
\begin{array}{ll} \cr
i_t = \sigma(W_{ii} x_t + b_{ii} + W_{hi} h_{t-1} + b_{hi}) \cr
f_t = \sigma(W_{if} x_t + b_{if} + W_{hf} h_{t-1} + b_{hf}) \cr
g_t = \tanh(W_{ig} x_t + b_{ig} + W_{hg} h_{t-1} + b_{hg}) \cr
o_t = \sigma(W_{io} x_t + b_{io} + W_{ho} h_{t-1} + b_{ho}) \cr
c_t = f_t \odot c_{t-1} + i_t \odot g_t \cr
h_t = o_t \odot \tanh(c_t) \cr
\end{array}
$$
where $h_t$ is the hidden state at time $t$,
$c_t$ is the cell state at time $t$,
$x_t$ is the input at time $t$,
$h_{t-1}$ is the hidden state of the layer at time $t-1$ or the initial hidden
state at time 0,
and $i_t$, $f_t$, $g_t$, $o_t$ are the input, forget, cell, and output gates, respectively.
$\sigma$ is the sigmoid function, and $\odot$ is the Hadamard product.
input, batch_sizes, sorted_indices, unsorted_indices = input
max_batch_size = batch_sizes[0]
if hx is None:
h_zeros = torch.zeros(
self.num_layers * num_directions,
max_batch_size,
real_hidden_size,
dtype=input.dtype,
device=input.device,
)
c_zeros = torch.zeros(
self.num_layers * num_directions,
max_batch_size,
self.hidden_size,
dtype=input.dtype,
device=input.device,
)
hx = (h_zeros, c_zeros)
else:
# Each batch of the hidden state should match the input sequence that
# the user believes they are passing in.
hx = self.permute_hidden(hx, sorted_indices)
result = _VF.lstm(
input,
batch_sizes,
hx,
self._flat_weights, # type: ignore[arg-type]
self.bias,
self.num_layers,
self.dropout,
self.training,
self.bidirectional,
)LSTM single cell of _VF.lstm:
std::tuple<at::Tensor, at::Tensor> _thnn_fused_lstm_cell(
const at::Tensor& input_gates,
const at::Tensor& hidden_gates,
const at::Tensor& cell_state_prev,
const c10::optional<at::Tensor>& input_bias,
const c10::optional<at::Tensor>& hidden_bias) {
// Apply biases if provided
auto gates = input_bias ? input_gates + *input_bias : input_gates;
gates += hidden_bias ? hidden_gates + *hidden_bias : hidden_gates;
return gates;
};
template <typename cell_params>
struct LSTMCell : Cell<std::tuple<Tensor, Tensor>, cell_params> {
using hidden_type = std::tuple<Tensor, Tensor>;
hidden_type operator()(
const Tensor& input,
const hidden_type& hidden,
const cell_params& params,
bool pre_compute_input = false) const override {
const auto& [hx, cx] = hidden;
if (input.is_cuda() || input.is_xpu() || input.is_privateuseone()) {
TORCH_CHECK(!pre_compute_input);
auto igates = params.matmul_ih(input);
auto hgates = params.matmul_hh(hx);
auto result = at::_thnn_fused_lstm_cell(
igates, hgates, cx, params.b_ih(), params.b_hh());
// applying projections if w_hr is defined
auto hy = params.matmul_hr(std::get<0>(result));
// Slice off the workspace argument (it's needed only for AD).
return std::make_tuple(std::move(hy), std::move(std::get<1>(result)));
}
const auto gates = params.linear_hh(hx).add_(
pre_compute_input ? input : params.linear_ih(input));
auto chunked_gates = gates.unsafe_chunk(4, 1);
auto ingate = chunked_gates[0].sigmoid_();
auto forgetgate = chunked_gates[1].sigmoid_();
auto cellgate = chunked_gates[2].tanh_();
auto outgate = chunked_gates[3].sigmoid_();
auto cy = (forgetgate * cx).add_(ingate * cellgate);
auto hy = outgate * cy.tanh();
hy = params.matmul_hr(hy);
return std::make_tuple(std::move(hy), std::move(cy));
}
};Transformer
Transformer excels at capturing long-range sequences. In deep learning, a transformer is a type of neural architecture that excels at processing sequential data like text or audio. It uses self-attention mechanisms to understand the relationships between elements in the sequence, allowing it to handle long-range dependencies effectively.
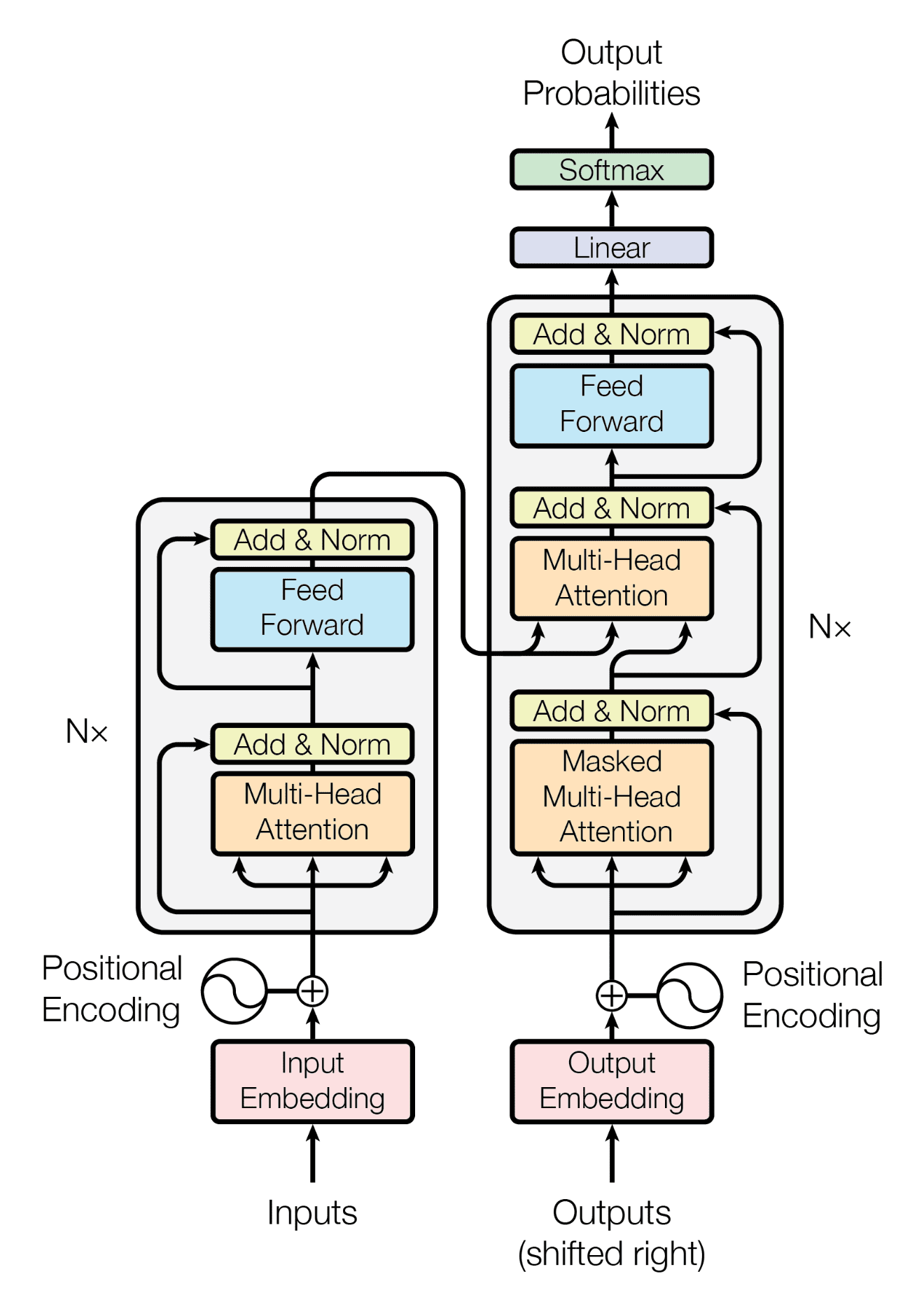
For details, please see Attention is what I first need.
Transformer vs. LSTM
The main difference lies in how they handle information flow and capture dependencies. LSTM excels at capturing long-term dependencies due to their internal memory cell and gates. Transformer uses a self-attention mechanism to process all input elements simultaneously, making them efficient for handling large-scale datasets and long-range dependencies.
Codes
Transformer = multi-head self-attention layer + MLP:
class MHSAttention(nn.Module):
# Multi-head Self-attention mechanism
def __init__(self, DimEmb, NumHead=8, DimHead=64, DropRate=0., bias=False):
super(MHSAttention, self).__init__()
DimModel = NumHead * DimHead # d_k = d_v = d_model/h = 64 (by default)
self.NumHead = NumHead
self.Scale = DimHead ** -0.5 # 1 / sqrt(d_k)
self.Softmax = nn.Softmax(dim=-1)
self.toQKV = Linearlayer(DimEmb, DimModel * 3, bias)
self.toOut = nn.Sequential(
Linearlayer(DimModel, DimEmb, bias),
Dropout(DropRate)
) if not (NumHead == 1 and DimHead == DimEmb) else nn.Identity()
def forward(self, x):
qkv = self.toQKV(x).chunk(3, dim=-1)
Query, Key, Value = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.NumHead), qkv)
x = torch.matmul(Query, Key.transpose(-1, -2)) * self.Scale # scaled dot product
x = self.Softmax(x)
x = torch.matmul(x, Value)
x = rearrange(x, 'b h n d -> b n (h d)')
return self.toOut(x)
# MLP
## Implementation of Feedforward model
self.linear1 = Linear(d_model, dim_feedforward, bias=bias, **factory_kwargs)
self.dropout = Dropout(dropout)
self.linear2 = Linear(dim_feedforward, d_model, bias=bias, **factory_kwargs)
self.norm_first = norm_first
self.norm1 = LayerNorm(d_model, eps=layer_norm_eps, bias=bias, **factory_kwargs)
self.norm2 = LayerNorm(d_model, eps=layer_norm_eps, bias=bias, **factory_kwargs)
self.dropout1 = Dropout(dropout)
self.dropout2 = Dropout(dropout)Reference
- What Are Foundation Models?
- Introduction of generative adversarial networks (GANs)
- Generative AI and its building blocks
- What is a foundation model?
- A Deep Dive into Small Language Models: Efficient Alternatives to Large Language Models for Real-Time Processing and Specialized Tasks
- Recurrent neural network (RNN) - Class Review
- RNN
- LSTM
- Attention is what I first need
- Large language model
- Transformer
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!